Exploring Text Segmentation Algorithms and Their Performance
Intro
In recent years, the internet has seen the emergence of numerous new podcasts. Some, like The Joe Rogan Experience, have gained immense popularity, while many others remain relatively unknown.
As a devoted podcast enthusiast, I am subscribed to more than 40 podcasts. Unfortunately, a considerable number of these podcasts lack proper timestamps for their episodes. A similar situation exists on YouTube, where a significant proportion of videos lack timestamps for their various sections.
This challenge has motivated me to embark on a new project that combines my passion for podcasts with my interest in machine learning. Operating under the working title of “automatic timestamps generator,” the primary goal of this project is to automatically segment podcast episodes into distinct topics and generate corresponding titles for each segment.
For this endeavor, I will use the Russian podcast DevZen, which delves into topics related to technology, software engineering, management, and databases.
Approaches
Various methods exist for text segmentation:
-
Supervised Learning:
- One approach involves determining whether a sentence is a boundary sentence. This can be done by creating an embedding for each sentence and training a binary classification model using these embeddings.
-
Unsupervised Learning:
- TextTiling, introduced by Marti A. Hearst in 1997, presents two scoring techniques for evaluating potential segment divisions: the block-comparison method and the vocabulary introduction method. The algorithm involves dividing the text into equally sized groups of pseudosentences and computing a score for each pair of groups.
- LCseg is an algorithm that works with both text and speech. Its core algorithm consists of two main components: a method for identifying and weighing strong term repetitions using lexical chains, and a method for hypothesizing topic boundaries based on simultaneous chains of term repetitions. For more information about this algorithm, you can read the paper “Discourse Segmentation of Multi-Party Conversation.”
- TopicTiling is a variant of the TextTiling algorithm that uses the Latent Dirichlet Allocation (LDA) topic model to split documents. It’s faster than other LDA-based methods, but it’s specific to certain topics and requires separate models for each subject. Since I plan to apply text segmentation to diverse podcasts covering technology, software engineering, movies, and music, this algorithm might not be the best fit for my project.
- GraphSeg attempts to construct a graph where each node represents a sentence, and edges connect two semantically related sentences. The algorithm then identifies all maximal cliques and merges them into segments.
- Another method is segmentation based on cosine similarity. Unsupervised Topic Segmentation of Meetings with BERT Embeddings article describes one of the possible options. The paper introduces an approach based on BERT embeddings. This algorithm is a modified version of the original TextTiling and detects topic changes based on a similarity score using BERT embeddings. The authors provide a reference implementation for the algorithm on their GitHub.
In this article, I will compare several of these methods using my own dataset: podcast episodes that have been transcribed and segmented into individual sentences.
However, I couldn’t find existing Python implementations for all the algorithms mentioned above. Therefore, I will only test a few of them:
- TextTiling: The algorithm’s implementation can be found in the NLTK library.
- LCSeg: I found only one implementation written in Elixir, but I had difficulty running it on Ubuntu.
- TopicTiling: Due to its limitations for specific subjects, I won’t be testing this algorithm.
- GraphSeg: There is at least one Python implementation available, called graphseg-python.
- For the “Unsupervised Topic Segmentation of Meetings with BERT Embeddings”, there are two Python implementations: one from the paper’s authors and another in the pyconverse library.
As an experiment, I will build segmentations for multiple podcast episodes using NLTK‘s TextTiling, graphseg-python, and the pyconverse library.
Segmentation methods comparison
All algorithms I’ll test on randomly selected 412th episode to find the best params (if there are any parameter exist for algorithm).
TextTiling
Let’s start from TextTiling from NLTK.
The TextTilingTokenizer implements TextTiling segmentation. Sadly the implementation has only block-comparison method.
TextTiling has two main parameters: pseudosentence size w and size of the block for the block-comparison method k. I’ll test multiple combination of these two parameters.
import math
import re
import warnings
warnings.filterwarnings("ignore")
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
from tqdm.notebook import tqdm
from stop_words import get_stop_words
import nltk
from nltk.metrics import windowdiff
from nltk.tokenize import texttiling
from nltk.tokenize.api import TokenizerI
from nltk.tokenize.texttiling import TokenSequence, TokenTableField, smooth
nltk.download('stopwords')
from pyconverse import SemanticTextSegmention
[nltk_data] Downloading package stopwords to /home/andrei/nltk_data...
[nltk_data] Package stopwords is already up-to-date!
df = pd.read_csv('../data/412_ep_reference.csv')
def text_tiling_windowdiff(df: pd.DataFrame, lang: str, text_tiling_tokenizer: TokenizerI, verbose: bool=False, **kwargs) -> None:
topic_df = df[[f'{lang}_sentence', 'ground_truth']].groupby('ground_truth').agg(topic=(f'{lang}_sentence', lambda x: '\n\n\t'.join(x)))
source_text = ' '.join(topic_df['topic'])
ground_truth = ''.join(topic_df['topic'].apply(lambda x: '|' + x.replace('\n\n', '').replace(' ', '')[1:]))
stop_words = get_stop_words(lang)
k = int(round(len(ground_truth) / (ground_truth.count('|') * 2.)))
metrics = []
segmentations = {}
sent_sizes = [20, 40, 80, 100, 200]
block_sizes = [10, 20, 40, 80, 100]
t = tqdm(total=len(sent_sizes) * len(block_sizes), disable=not verbose)
for sent_size in sent_sizes:
for block_size in block_sizes:
ttt = text_tiling_tokenizer(stopwords=stop_words, w=sent_size, k=block_size)
topics = ttt.tokenize(source_text)
actual = ''.join(['|' + topic.replace('\n', '').replace(' ', '')[1:] for topic in topics])
assert len(ground_truth) == len(actual)
win_diff = windowdiff(ground_truth, actual, boundary="|", k=k)
metrics.append({
'algorithm': 'text_tiling',
'lang': lang,
'topics_count': len(topics),
'k': k,
'sent_size': sent_size,
'block_size': block_size,
'win_diff': win_diff,
})
segmentations[(sent_size, block_size)] = topics
t.update(1)
return pd.DataFrame(metrics), segmentations
def find(s: str, ch: str):
return [i for i, ltr in enumerate(s) if ltr == ch]
def plot_segmentation(ground_truth_topics: list[str], actual_topics: list[str], title: str) -> None:
source_text = re.sub('\s+', '', ''.join([f'|{x[1:]}' for x in ground_truth_topics]))
actual_text = re.sub('\s+', '', ''.join([f'|{x[1:]}' for x in actual_topics]))
source_idx = find(source_text, '|')
actual_idx = find(actual_text, '|')
idx_df = pd.DataFrame({
'idx': source_idx + actual_idx,
'source': ['ground_truth'] * len(source_idx) + ['actual'] * len(actual_idx),
'y': [0.] * len(source_idx) + [0.] * len(actual_idx)
})
sns.set(rc={'figure.figsize':(13.7,2.5)})
sns.scatterplot(data=idx_df, x="idx", y="y", hue="source", style='source', sizes=(80, 400), s=120)
plt.legend(title=title, fontsize='9', title_fontsize='10')
Russian text segmentation
ru_text_tiling_metrics_df, ru_text_tiling_segments = text_tiling_windowdiff(df, 'ru', texttiling.TextTilingTokenizer, verbose=True)
ru_text_tiling_metrics_df
| algorithm | lang | topics_count | k | sent_size | block_size | win_diff | |
|---|---|---|---|---|---|---|---|
| 0 | text_tiling | ru | 6 | 4759 | 20 | 10 | 0.421814 |
| 1 | text_tiling | ru | 5 | 4759 | 20 | 20 | 0.421814 |
| 2 | text_tiling | ru | 5 | 4759 | 20 | 40 | 0.421814 |
| 3 | text_tiling | ru | 5 | 4759 | 20 | 80 | 0.421814 |
| 4 | text_tiling | ru | 5 | 4759 | 20 | 100 | 0.421814 |
| 5 | text_tiling | ru | 4 | 4759 | 40 | 10 | 0.420854 |
| 6 | text_tiling | ru | 4 | 4759 | 40 | 20 | 0.421814 |
| 7 | text_tiling | ru | 4 | 4759 | 40 | 40 | 0.421814 |
| 8 | text_tiling | ru | 4 | 4759 | 40 | 80 | 0.421814 |
| 9 | text_tiling | ru | 4 | 4759 | 40 | 100 | 0.421814 |
| 10 | text_tiling | ru | 2 | 4759 | 80 | 10 | 0.413459 |
| 11 | text_tiling | ru | 2 | 4759 | 80 | 20 | 0.413459 |
| 12 | text_tiling | ru | 2 | 4759 | 80 | 40 | 0.413459 |
| 13 | text_tiling | ru | 2 | 4759 | 80 | 80 | 0.413459 |
| 14 | text_tiling | ru | 2 | 4759 | 80 | 100 | 0.413459 |
| 15 | text_tiling | ru | 2 | 4759 | 100 | 10 | 0.412608 |
| 16 | text_tiling | ru | 2 | 4759 | 100 | 20 | 0.412608 |
| 17 | text_tiling | ru | 2 | 4759 | 100 | 40 | 0.412608 |
| 18 | text_tiling | ru | 2 | 4759 | 100 | 80 | 0.412608 |
| 19 | text_tiling | ru | 2 | 4759 | 100 | 100 | 0.412608 |
| 20 | text_tiling | ru | 1 | 4759 | 200 | 10 | 0.396908 |
| 21 | text_tiling | ru | 1 | 4759 | 200 | 20 | 0.396908 |
| 22 | text_tiling | ru | 1 | 4759 | 200 | 40 | 0.396908 |
| 23 | text_tiling | ru | 1 | 4759 | 200 | 80 | 0.396908 |
| 24 | text_tiling | ru | 1 | 4759 | 200 | 100 | 0.396908 |
ru_ground_truth = df[['ru_sentence', 'ground_truth']].groupby('ground_truth').agg(topic=('ru_sentence', lambda x: ' '.join(x)))['topic'].values
en_ground_truth = df[['en_sentence', 'ground_truth']].groupby('ground_truth').agg(topic=('en_sentence', lambda x: ' '.join(x)))['topic'].values
def plot_segmentation_for_best_score(
metrics_df: pd.DataFrame,
segmentation: dict,
algorithm_params: list[str],
ground_truth: list[str],
title: str)-> None:
min_win_diff_row = metrics_df[metrics_df['win_diff'] == metrics_df['win_diff'].min()]
win_diff, topics_count, *params = min_win_diff_row[['win_diff', 'topics_count'] + algorithm_params].values[0]
plot_segmentation(ground_truth, segmentation[tuple(params)], title=f'{title} (best params: {tuple(params)})')
plot_segmentation_for_best_score(ru_text_tiling_metrics_df, ru_text_tiling_segments, ['sent_size', 'block_size'], ru_ground_truth, title='TextTiling')
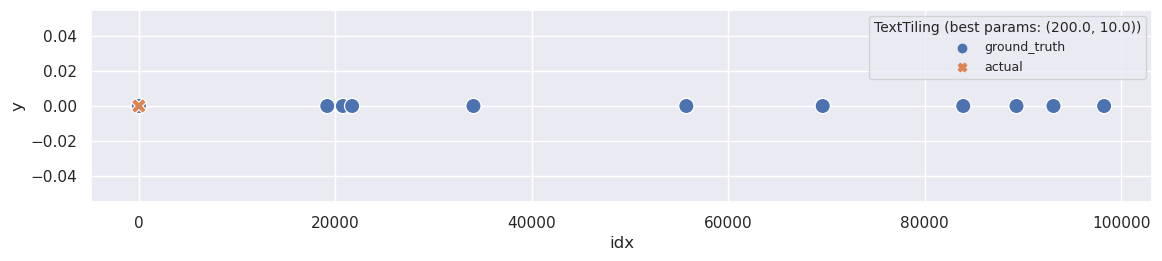
There are two strange things about the metric when applied to Russian text. Firstly, the WindowDiff score changes only with different sent_size settings and doesn’t consider block_size. Secondly, the best WindowDiff score is achieved when the text is not segmented at all. It seems like this implementation doesn’t work well for non-English texts.
So, this is the reason to take a closer look at the TextTiling implementation in the NLTK library. The code in the TextTilingTokenizer class is quite understandable, and the main area of concern lies in lines 94-97 of the tokenize method:
# Remove punctuation
nopunct_text = "".join(
c for c in lowercase_text if re.match(r"[a-z\-' \n\t]", c)
)
As you can see, all non-Latin letters are removed during this preprocessing step. Unfortunately, this fact renders the TextTilingTokenizer ineffective for all non-Latin languages, including Cyrillic languages like Russian.
The simplest way to “fix” this issue is to duplicate the class and modify this preprocessing step accordingly. The whole source code you can find under the spoiled below.
TextTilingTokenizerExt
ru_text_tiling_ext_metrics_df, ru_text_tiling_ext_segments = text_tiling_windowdiff(df, 'ru', TextTilingTokenizerExt, verbose=True)
ru_text_tiling_ext_metrics_df
| algorithm | lang | topics_count | k | sent_size | block_size | win_diff | |
|---|---|---|---|---|---|---|---|
| 0 | text_tiling | ru | 167 | 4759 | 20 | 10 | 1.000000 |
| 1 | text_tiling | ru | 182 | 4759 | 20 | 20 | 1.000000 |
| 2 | text_tiling | ru | 178 | 4759 | 20 | 40 | 1.000000 |
| 3 | text_tiling | ru | 164 | 4759 | 20 | 80 | 1.000000 |
| 4 | text_tiling | ru | 172 | 4759 | 20 | 100 | 1.000000 |
| 5 | text_tiling | ru | 86 | 4759 | 40 | 10 | 0.970591 |
| 6 | text_tiling | ru | 84 | 4759 | 40 | 20 | 0.990854 |
| 7 | text_tiling | ru | 79 | 4759 | 40 | 40 | 0.991524 |
| 8 | text_tiling | ru | 85 | 4759 | 40 | 80 | 1.000000 |
| 9 | text_tiling | ru | 82 | 4759 | 40 | 100 | 0.963816 |
| 10 | text_tiling | ru | 43 | 4759 | 80 | 10 | 0.932116 |
| 11 | text_tiling | ru | 43 | 4759 | 80 | 20 | 0.892820 |
| 12 | text_tiling | ru | 43 | 4759 | 80 | 40 | 0.908521 |
| 13 | text_tiling | ru | 40 | 4759 | 80 | 80 | 0.949377 |
| 14 | text_tiling | ru | 37 | 4759 | 80 | 100 | 0.799840 |
| 15 | text_tiling | ru | 34 | 4759 | 100 | 10 | 0.807385 |
| 16 | text_tiling | ru | 32 | 4759 | 100 | 20 | 0.710632 |
| 17 | text_tiling | ru | 32 | 4759 | 100 | 40 | 0.846590 |
| 18 | text_tiling | ru | 30 | 4759 | 100 | 80 | 0.732066 |
| 19 | text_tiling | ru | 31 | 4759 | 100 | 100 | 0.780127 |
| 20 | text_tiling | ru | 17 | 4759 | 200 | 10 | 0.516336 |
| 21 | text_tiling | ru | 16 | 4759 | 200 | 20 | 0.443728 |
| 22 | text_tiling | ru | 18 | 4759 | 200 | 40 | 0.519368 |
| 23 | text_tiling | ru | 16 | 4759 | 200 | 80 | 0.446840 |
| 24 | text_tiling | ru | 17 | 4759 | 200 | 100 | 0.485716 |
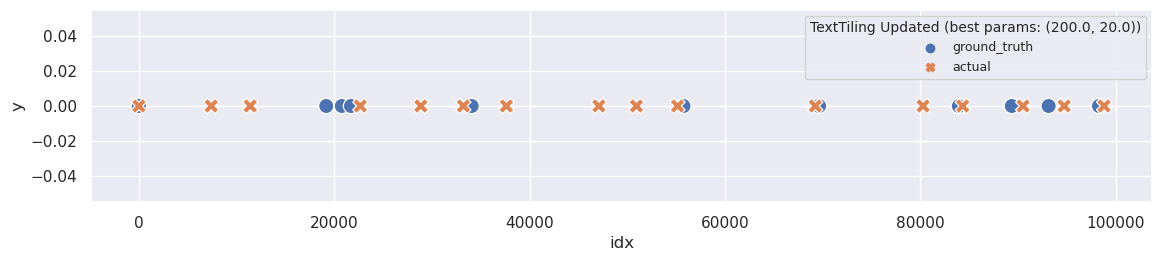
plot_segmentation_for_best_score(ru_text_tiling_ext_metrics_df, ru_text_tiling_ext_segments, ['sent_size', 'block_size'], ru_ground_truth, 'TextTiling Updated')
def print_segmentation(segmentation: list[str], limit: int=100) -> None:
def _get_words(segment_text: str) -> list[str]:
return segment_text.replace('\n\n', ' ').split()
def _limit_by_words(segment_words: list[str]) -> str:
words = segment_words[:limit//2] + [' [...] '] + segment_words[-limit//2:]
return ' '.join(words)
for segment in segmentation:
print(_limit_by_words(_get_words(segment)), end='\n\n')
print_segmentation(ru_text_tiling_ext_segments[(200, 20)], limit=130)
Всем привет! Вы слушаете подкаст DevZen выпуск номер 412, записанный 6 февраля 2023 года. Записываемся как всегда полным составом, кроме Светы, кроме Вани. Подкаст теперь есть на Spotify, если вы пропустили последний выпуск. А со мной этот подкаст ведет Валера. Здравствуй, Валера! Привет! Привет! Сколько у нас теперь слушателей на Spotify? Слушай, я еще не заходил. Вот хороший вопрос. Пока мы будем о чем-то говорить, [...] она почему-то добавляет тебе раскладку клавиатуры, которая соответствует региону твоего ключа, а не региону, которая у тебя выбрана в локале. И у меня, поскольку я вот нахожусь в Ирландии, у меня лицензия ирландская, и соответственно периодически в добавок к американской клавиатуре и русской клавиатуре мне добавляется еще ирландская клавиатура, которая тоже квертина, у нее все символы перепуданы, они не в тех местах, где нормальных людей.
И это дико бесит, у тебя во-первых, ломается мышечная память, потому что у тебя внезапно две английских раскладки. Нажимаешь переключить раскладку, у тебя опять английская. А во-вторых, кнопки не в тех местах неудобно. И есть магический файл-реестер, который можно запустить, перезагрузить к компьютеру, и это хрен не исчезнет. Никакого другого способа ее удалить нет. Этому багу, наверное, уже лет шесть его никто не чинит. И, [...] нужно постараться, чтобы не стригерить вакуум, который будет пытаться победить приближение к СИДРапарамда. То есть у тебя СУБД не стартует с каким-нибудь локом на таблице, который предотвратит запуск вакуума. И за этим нужно внимательно следить. Краткое содержание, у меня есть сомнения, насколько нужно использовать этот прием, но если вы прям очень сильно торопитесь или просто хотите изучить, как это выглядит, то имеют право на жизнь.
Поэтому по этой части вопрос и возражение в комментариях. Спасибо, что притащил. Мне это было бы полезно, наверное, летом. Буду чем-ли прошлым. В прошлом. Могу я поинтересоваться, чем ты занимался? Ну, нам нужно было, не лично я, нам нужно было потестировать, как наша пипяка ведет себя при приближении к СИДРапарамда. Валера, и рассказ, что я делал этим летом. Вот. И последнее. Последнее от меня. Я [...] правила, потому что давно про Games Jams не говорили. В общем, конкретно у Global Games Jams идея такая. У вас есть обычно 48 часов. В этом году у некоторых ситуаций была неделя, но мы в 48 часовом формате делали. Вот. У вас есть 48 часов. Вы подбираете, когда вы стартуете, вам дается абстрактная идея, и вам за 48 часов вокруг этой идеи нужно сделать игре.
Желательно работающий. Это не какое-то соревнование, просто вы сделали игре через 48 часов и смогли показать. Поздравляем, вы прекрасны и великолепны. В принципе, ничто не мешает вам участвовать в онлайне, и некоторые так даже делают. Мне очень нравится формат берлинской площадки. Я организую ребята, которые, кажется, называются GameStorm Berlin. Вот. И я не знаю везде ли так, потому что я преимущественно на берлинской площадке всегда [...] может понять движение тебя по полу, когда ты изображаешь червя. Я тоже. Вот прикиньте, вдруг у них правда был такой test-case. Вот. Я... Если вы всегда хотели делать игры, я вам настоятельно рекомендую попробовать поучаствовать в какой-нибудь такой движухе, потому что, во-первых, вы можете присоединиться к команде, которая уже что-то умеет, и тогда вам будет чуть менее страшно, и вас, возможно, чему-то даже немножко научат.
Правда, желательно все-таки на ваш инструментарий посмотреть заранее. Во-вторых, это один из крутейших командных экспериментов, потому что, когда у вас есть 48 часов... То есть почему мне нравится этот формат? Я тут задумался над этим вопросом, почему я не участвую в каких-нибудь других джемах. Во-первых, 48 часов – это достаточно короткий промежуток времени, чтобы не успеть уйти в какой-нибудь в вирн-инжиниринг или космические еи. С [...] я дефолтными прямоугольниками примерно выстраивал интерфейс, который бы примерно соответствовал их макету, а потом уже, когда они выгрузили по слоям и по отдельным, как это, отдельным ассетам, я уже заменил дженерик прямоугольники с Herp image, заменил на какие-то... ну, как раз, собрал это в полноценные префабы в Unity. Ну, все, что я могу сказать, это дикий респект тем, кто ухитряется сделать игру за 48 часов.
Ну, чего, у нас таких много, но спасибо. Но опять же, нужно понимать, это же не какая-то прям огромная игра, то есть у нас есть четыре персонажа, которые приходят поговорить, что-то типа, наверное, сотни линий диалога написанных, вот, не то чтобы... картинка в основном статичная, конкретно у нас там нет очень много анимации, ну, то есть это, очевидно, дубл вещь, ну, то есть, да, ты [...] Это Bulkhead Concurrency, который видимо отвечает за то, сколько параллельных запросов может быть к базе данных открыто в каждую единицу времени. И Bulkhead Queue, видимо, количество запросов, которые ожидают обработки. Соответственно они подумали, что видимо вот этот Legacy-фасад, его лимиты слишком жесткие, мы не успеваем обрабатывать заказы, и поэтому давайте поднимем эти лимиты, чтобы весь имеющийся наплыв пользователей прососался, и все успокоится и станет хорошо.
Лимиты были подняты, касса временно приподнялась, а потом все легло обратно. После того, как они убедились, что увеличение лимитов Bulkhead не помогает, они его понизили обратно, как было, и в этот момент они вроде как пришли к гипотезе о том, что нагрузка на базу данных, она выше того, что у них когда-либо было, и возможно просто база данных не тянет, несмотря на то, что они [...] них есть вот эта центральная монолитная база данных, у которых есть физические пределы масштабирования, и по возможности вытаскивать ее из критического пути заказа, особенно таких вещей, которым не важна там строгая консистентность или что-то еще, или которые редко меняются, это очень важно, потому что это просто уменьшает нагрузу на вашу бутылочку, нагрузку на вашу бутылочную горлышко, и таким образом позволяет вам масштабироваться лучше и больше.
Вот, что они сделали, это они заметили, что в ходе инцидента у них значительную часть нагрузки создавал запрос на создание меню, и обычно меню у них кэшируется в памяти вот в этом их legacy-фасаде, но из-за того, что они его перезапускали несколько раз по ходу инцидента, опять же этот кэш был сброшен, и куча запросов прорвалась в базу, по сути, чтобы вытащить одно и то [...] тебя тоже похожие истории бывали. С одной стороны, да, я довольно много всяких страданий испытывал, но с другой стороны, ты всегда можешь сделать какие-то лоутеях решения, мне кажется, часть страданий, я не знаю, как у них стэк, но очень часто страдания происходят из-за того, что люди идут за кем-то очень хай-тэк решением, а можно было бы быстрее из говна и палок, но это работало бы.
Ну, не знаю, мне не кажется, что у них, по крайней мере из тех диаграмм, которые они нарисовали в статье, мне не кажется, что у них прям микросервис и микросервисом сгоняет, у них довольно разумное разделение по компонентам. Просто смотри, в чем по монолитусу. Короче, извини, что перебиваю, че я хотел сказать, что на микросервисах реально лоутшединг сделать, ты можешь каждому отделему микросервиса сделать лоутшединг, [...] что ой, как много файловых дискрипторов. Я, ну, я, честно говоря, не ДБ, я не занимаюсь администрированием систем, но из того, что я вот слышал, вообще мне неизвестна ситуация, когда люди сталкивались с проблемой, что ой, у нас там кончились файловые дискрипторы или что-то. Ну вот тебе Postmortem рассказывает про такую ситуацию, я лично такой налетал. Ну вот этот Postmortem, он про другую особо, да.
Ну да, но тут проблема не в том, что у тебя дискрипторы в операционной системе кончились, тут проблема была в том, что у тебя кэш дискрипторов исчерпался, и потом тебе приходилось их постоянно открывать, а открывать файлы это дорого. Вот этот кэш он реализован в мочекуле, как я понимаю. Да, а в Postgres такого кэша нет? Это хороший вопрос. Я... Мое интуитивное ожидание, что Postgres, [...] к этому разработчику и сказать ему, что ему надо делать, потому что вот я прямо чувствую это лучше всего для компании. Но это самообман. Но сказать, что это самообман, себе могут очень немногие. Вот. А расти надо вместе с компанией, и расти надо в тем направлении, в которых ты не знаешь, куда расти, я думаю, это основная причина, почему executive не умеют делать работу executive.
Я, то, я не считайте меня супер ровным, я тоже не смогу работать как executive, я, не дай бог, я не пойду туда. Вот. Но я, когда я вижу в некоторых случаях, как, какие решения и какие поступки, я понимаю, что, ну, этот человек просто не дорос до своего места. Или перерос. Или, или еще что-нибудь, но я вообще понятно изъясняюсь. Ну, в целом, да. [...] lossless с компрессией, ну, на текущей камере, предыдущая камера не умела в lossless с компрессией, поэтому там я выбирал, если это ночные фотографии или просто какая-то сложная ситуация, которую потом планирую жестоко редачить, я снимал так, что там было что-то типа по 30-40 мегабайт на... нет, да, на 30-40 мегабайт на ровку, но я обычно их храню, сжимаю всю папку, и такие ровки хорошо сжались.
Сейчас у меня камера немножко другая, у нее крупнее сенсор, она, к счастью, умеет в lossless сжатые ровки, поэтому я почти никогда не переключаюсь из этой опции, потому что я не снимаю спорт, поэтому я на скорость записи на диск, следуя на флажку. Сейчас у меня, по-моему, пожатые 30-40 мегабайт. Ага, понятно. Ну, вот, не знаю, мне все еще кажется, что 30-40 мегабайта — это [...] показать. Что еще можно показать? Это эссоциативные сервера, в которые ты логинился. Ага. Эм, это интересная тема, которая, кажется, занес в темы слушателей несколько выпусков назад, но трюк не прокатил. Идея в следующем. Во-первых, ну, достаточно хорошо известен факт, что на GitHub можно для любого юзернейма посмотреть зарегистрированные публичные ключи. GitHub.com slash username.keys и там весь список публичных ключей, которые ты добавил в свой GitHub.
Это OK, потому что теоретически ключи публичные, поэтому с ним ничего опасного сделать нельзя. Ничего не раш... Нельзя авторизоваться, то и вене, все такое. Вот. Соответственно, через GitHub API, в принципе, не очень сложно написать бота, который просто обойдет всех пользователей GitHub и соберет базу данных, username, ключ. А дальше начинается интересное, что с этой базой данных можно делать. Как работает SSH-продокол при аутентификации ключом? [...] случае, конечно, известно, у него много трейс... как это сказать... источников трейспойнтов. И для heavyweight локов используется Uprobs. Uprobs это фактически... я сразу скажу, я как бы нифига не эксперт в BPF, это мое дежурнанское понимание, что ты, имея отладочные символы и исполняемый файл, можешь определить, где в этом исполняемом файле примерно находятся те или иные функции, и возможно даже определить смысл аргументов этих функций.
И с помощью какой-то офигенной магии, которая мне неизвестна, понять, что если я вот в бинарнике зашел вот в это место, значит, произошел вызов этой функции. Если я вернулся с того-то места, то значит, у меня эта функция вернула результат. И Uprobs он как раз... то есть Uprobs не работает как-то специально с генитированным бинарником. Uprobs работает в принципе с любым бинарником, для которого у [...] есть память, которая поближе к нам, память, которая ближе к другому сокету. Как операционная система решает, где выделить память при вызове молока? Ну, молок, он сам по себе не обязательно же память у операционной системы просит, он может из уже выделенной выделить тебя, правильно? Возможно... Допустим... Да, прости, допустим, мы знаем, что мы его вообще первый раз вызываем, и у нас нет свободной освобожденной памяти.
Ну, тогда это, соответственно, запрос пойдет в ядро. Ядро, наверное, знает, на каком сокете мы выполняемся, и может попробовать выделить память, которая поближе. Я не знаю, достаточно ли Linux умный, чтобы так делать, но, кажется, противоподобны гипотезы. Это хороший ответ, и мой ответ звучал бы так же, но я посмотрел доклад, и занимательный ответ. Когда ты вызываешь молок и уходишь в ядро, ядро выделяет память [...] Просто все принесли темы в Spotify, а не в Telegram, а ты не смотришь в Spotify. Это бы многое объясняло. Хитрый слушатель без имени, которое можно увидеть, пишет «Уважаемые ведущие, расскажите, пожалуйста, какие темы можно приносить?» Любые технически, пожалуйста. Ну в смысле там просто не то, что можно и нельзя, а с какой... он там был формулирован так, что какой шанс, что мы что-то обсудим?
То есть чтобы приносить темы, которые мы прочитаем и не просто скажем «Ок». И в качестве примеров варианты, ну может, значит, типа спостить как выше там делалов в контексте, как про переписание фиш на расти, даст создан быть темой или нет, или вот, например, задача по работе и не могу найти хорошего рихитектурного решения, или ткнуться на пост десятилетней давности, где автор довольно интересно набрасывает [...] приноси. Нет, не буду. А ты приноси. Я буду приносить, не буду их рассказывать. Вот это просто самое лучшее, что можно сделать, не надо так. Лучше не приноси, но рассказывай наши. Ну ладно, я буду хорошим. И на этой ноте мы с вами прощаемся. DevZen.ru Telegram. Заходите в Spotify, добавляйте нам темы в Spotify, ну лучше в Telegram. Всем пока и до следующего выпуска. Пока.
Alright, now it appears much improved. The algorithm has successfully divided the text into more than one segment. Furthermore, this segmentation seems quite impressive, as the original segmentation was at a high level, but TextTiling has extracted more detailed segments.
English text segmentation
en_text_tiling_metrics, en_text_tiling_segments = text_tiling_windowdiff(df, 'en', text_tiling_tokenizer=texttiling.TextTilingTokenizer, verbose=True)
en_text_tiling_metrics_df = pd.DataFrame(en_text_tiling_metrics)
en_text_tiling_metrics_df
| algorithm | lang | topics_count | k | sent_size | block_size | win_diff | |
|---|---|---|---|---|---|---|---|
| 0 | text_tiling | en | 197 | 4713 | 20 | 10 | 1.000000 |
| 1 | text_tiling | en | 198 | 4713 | 20 | 20 | 1.000000 |
| 2 | text_tiling | en | 204 | 4713 | 20 | 40 | 1.000000 |
| 3 | text_tiling | en | 198 | 4713 | 20 | 80 | 1.000000 |
| 4 | text_tiling | en | 188 | 4713 | 20 | 100 | 1.000000 |
| 5 | text_tiling | en | 100 | 4713 | 40 | 10 | 1.000000 |
| 6 | text_tiling | en | 98 | 4713 | 40 | 20 | 0.999060 |
| 7 | text_tiling | en | 94 | 4713 | 40 | 40 | 0.993129 |
| 8 | text_tiling | en | 97 | 4713 | 40 | 80 | 0.999060 |
| 9 | text_tiling | en | 97 | 4713 | 40 | 100 | 0.998222 |
| 10 | text_tiling | en | 50 | 4713 | 80 | 10 | 0.980307 |
| 11 | text_tiling | en | 50 | 4713 | 80 | 20 | 0.952136 |
| 12 | text_tiling | en | 47 | 4713 | 80 | 40 | 0.902969 |
| 13 | text_tiling | en | 49 | 4713 | 80 | 80 | 0.925158 |
| 14 | text_tiling | en | 44 | 4713 | 80 | 100 | 0.864128 |
| 15 | text_tiling | en | 38 | 4713 | 100 | 10 | 0.933443 |
| 16 | text_tiling | en | 40 | 4713 | 100 | 20 | 0.880860 |
| 17 | text_tiling | en | 36 | 4713 | 100 | 40 | 0.797904 |
| 18 | text_tiling | en | 37 | 4713 | 100 | 80 | 0.823327 |
| 19 | text_tiling | en | 37 | 4713 | 100 | 100 | 0.778070 |
| 20 | text_tiling | en | 19 | 4713 | 200 | 10 | 0.645603 |
| 21 | text_tiling | en | 19 | 4713 | 200 | 20 | 0.553795 |
| 22 | text_tiling | en | 19 | 4713 | 200 | 40 | 0.524129 |
| 23 | text_tiling | en | 20 | 4713 | 200 | 80 | 0.614289 |
| 24 | text_tiling | en | 20 | 4713 | 200 | 100 | 0.600073 |
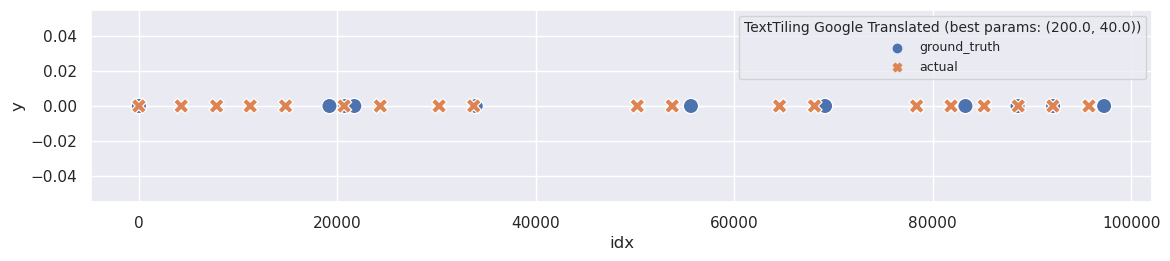
The most disappointing aspect is that the original segmentation had far fewer topics. Nonetheless, it would be interesting to explore the topics we obtain with the best parameters:
plot_segmentation_for_best_score(en_text_tiling_metrics_df, en_text_tiling_segments, ['sent_size', 'block_size'], en_ground_truth, title='TextTiling Google Translated')
print_segmentation(en_text_tiling_segments[(200, 40)], limit=130)
Hi all! You listen to the Devzen podcast issue number 412, recorded on February 6, 2023. We sign up as always with a full composition, except for Sveta, except Vani. There is now a podcast on Spotify if you missed the last issue. And with me this podokast is leading Valera. Hello, Valera! Hello! Hello! How many listeners do we have on Spotify now? Listen, [...] will re -switch again. Here, and yes, this is perhaps this is a factor that I work in a large company, but such events happen. In fact, the same thing. And at this moment we are scumbaging about Default. A... What else did I learn this week? This is how to correctly free the divided memory under MacOS. Postgres has such a feature that ...
I guess, the answer will preload, right? Oddly enough, no. Postgres has such a feature that it uses a separated memory that is from Postgres, a divided memory that stands out with a scimget request. He used to use it very much, but now he uses it less, and highlights it through MUP, but to find this for a small sewn memory, you still need [...] is a magic file-player that can be launched, restart to the computer, and this hell will not disappear. There is no other way to remove it. This Baga, probably, has not been repairing it for six years now. And, apparently, do not clean ... So. In general, in the Republic of Ireland, how many people use the Irish language and the layout of the corresponding?
Well, the layout is an English layout, that is, it is an ENUS layout corresponding to the ENUS location, and there is ENUK and ENIE. That is, they are similar, this is also an ordinary qwerty layout, just there are dogs, points with a comma, interest they are slightly replaced. The dollar sign is replaced, not a foot sign. UK layouts and UK layouts are [...] is, your DBMS does not start with any lock on the table that prevents the launch of the vacuum. And you need to carefully monitor this. A brief content, I have doubts how much you need to use this technique, but if you are in a hurry to rush very much or just want to study how it looks, then have the right to life.
Therefore, in this part, the question and objection in the comments. Thank you for dragging. It would probably be useful to me, probably in the summer. I will be something of the past. In past. Can I ask what you did? Well, we needed, not personally, I needed to test how our Pipika behaves when approaching Sidrapara. Valera, and the story what I did this [...] recently, we are used to the fact that startups are measured by a metric called the Year Over Year Growth. And this is all that they showed on slides within themselves other people, investors, that’s all. In the current difficult economic situation, when everyone is dismissed, suddenly people thought that effectiveness is also an important business indicator, especially when business is older than 2-3 years.
In general, the thing I want to say about, I will not try to explain, but the indicator is called Burn Multiple. And if you have less one, then you earn money much faster than you spend it. If a single or one and a half, well, like a startup will go. One and a half to two, well, you can still live. If you [...] update the link to the branch, and theoretically it will be more simple than if you had to do it with your hands. In practice, this is all the same, it seems to me, a very low-level tool, and Git, it is so cool, it can be a lot, but for some reason it is always so uncomfortable, and this is just a classic Git.
Somehow, in general, I corrected my earlier mistake, if someone is interested, please use, I have a good article that explains how to do it correctly. Thank you, I also have erata, we used to talk about one -payers on RISK5, is called Vision5.2, and Erata is that it seems to be a demand exceeded the offer, and the seller on AliExpress now sends customers [...] very impressive, usually. There was a topic this time Korn. Our team turned out to be such that there were two programmers, both of which are related to jams only on the development of games. Just before that, in the 16th and 18th years, I participated with my colleagues in Woogie, and there, as a rule, there were Timmates who have good experience with Unity.
In the 16th year, I did a backing end in general, and at 18 I was on the patch. In the 19th year, it turned out so successfully that the idea, in principle, fell well on the fact that Unity can do that. And this time we had two inexperienced university programmers, and the things that I got ... I already thought that ... I [...] every time in the last hours in front of the deadline, a working build is obtained. This is just the absolute magic of Jem. How does this process look like? You, like, everyone saw your own independent component or ... Well, look, first you need to draw a line that you have ... The team usually has artists yet, and someone there, for example, writers.
These people, in principle, work with other tools, but artists draw, and you usually communicate with them. That is, I do UI, I talked with the artist who was engaged in UI elements. The person who writes, he always talked with a programmer who wrote game mechanics, so that the person who writes writes in Json some kind of such plate, and this tablet was [...] blocks to the page with CSS. No, well, I spent a lot of time. I said there before the podcast that I could not ... Or even now I mentioned that I could not do UI for one thing for one thing because I spent a lot of time in another place in UI, because I am not a specialist, because UI works in Unity.
Well, yes, you sometimes get in a day for some dull garbage. Sorry, I interrupted you. And, no, no, I said everything. I think that we very productively discussed Game Jam. This is wonderful. And what else is fine? This is a fall and postmortum. Oh yeah. OK. This is the topic that I saw on Habria a few weeks ago, it seems. This is [...] not. Well, while the microservices they convinced, for some reason. Until you have such a wonderful outline that will say, well, look, we have lost so many millions of rubles, and let's drink these features to drink. Microservices there most often Pich is that well, let's cut it, and we will cut them more sharply, because now we can saw feathers in each microservice separately.
This management often loves and understands. But the fact that the log-editing, there are settings, this all sounds boring, does not bring money, and therefore people are like that, yes, this is a good idea, well, let's put it somewhere in the end of the quarter, and at the end of the quarter Such, a, fucking, we will not smile in the features, let's, in [...] Service, this is an interesting topic. Well, by the way, as I understand it, they had this opportunity, because they have different these sources through different microservices. Ahhh, I understand. Well, in fact, then I will return to my sketch that Sasha wanted to make, and tell me, Sasha, and in Postgres there is also no such system as to the file on the table?
There are many files per table. Depends on the size. That is, you have in Postgres, when you compile it, you set the configuration parameter, or the one who collects you in the package, sets the configuration parameter, is called the size of the segment. By default, it is 1 gigabyte, and if you have more than 1 gigabyte in the damp data table, then [...] I have some thoughts, they are not all funny, but it seems to me that in general the article is good. The problem is that, I don’t know, maybe I work in an uncompanational company, but it never works like that. Exects always make decisions on and without reason. And, to be honest, these solutions are strongly outside the establishment of culture and its information.
PED, it seems, somewhere I read a similar article or an article on a similar topic, for about the same reason as you, Valera, but there was just about what exectives are doing and, like making a person a good candidate In exectives. And there was an interesting idea that in fact everything that execute is doing, or rather their professional skill, is that, because [...] it seems to me that in this functionality you need to do so -That. Well, because the company is small, really, he communicates with clients, he is more Executive, he is a seller, he is a consultant, and therefore he understands. When the company already becomes for 50 people, this is not at all its field of activity, and it should no longer do this.
And now, where to stop? At what point should he stop doing this? This is some kind of signal to give, because for many, I don’t know how to express it correctly, power, it returns a little, that is, as if, in this case, executive actually has a lot of powers and a lot of responsibility , a lot of power. He can do some [...] you have, it has a lot of USE CASs of different use, and as a result it is possible to cover it very hard, or it is not generally impossible to cover, I don’t know. Just look, cloud storage, especially the one that just files lie on the cloud on the cloud and is not locally with you, it just provides it just provides everything.
Drupbox, he is one of his distinguishing features from all other services, that is, I don’t know, again, again, especially if you are a business, you can be cheaper to buy the whole Google Apps package at once, which is still not to pay for Drupbox, because This is now the fact that the data is always locally, relevant, well synchronized, and not just that [...] I still have, since I have export photos, I can about it about when I shot something, and go and unzip the desired folder. Here, but then you are exporting already processed photos to one place, or what? Yes, in Durbox too. And then in this one place with the help of what do you look at common pictures? I just have addictions, in short.
Firstly, I have a flour, and secondly, I have a durbox, and you can just make an open appearance of the photo and look through your pictures in time. I still have a naming system, I am more or less if I imagine when it was about, I can just navigate for the year. Well, that is, I have a folder of photography so that [...] good libraries of some such things. This server, it can violate the protocol of authentication with keys in the sense that he does not really check your keys, he just has this database with GitHub, and if he finds a public key that is matched to one of the GitHub nicknames, then He will just say Okay, okay, I authorize you, dude, with this key.
Here, and so, if you are SSH-are in this modified server, then the server can find out your nickname on Github. You used the same public key that you have registered with GitHub. So far, while everyone is watching, right? Everything is clear? Here. Now a more disturbing variation on this topic begins. It consists in the fact that Okay, well, for example, we wrote [...] only me? Well, I was interested to hear it, because when you brought it for the first time, I somehow did not read it like that. Thank you for going. Here, dear listeners, you see, we did not fully turn the topic, and we can come and expand it more fully. What else can be expanded, this topic is not in the bookmark for retelling.
Firstly, I have a colleague Yang, Jan Nedvedsky, in my opinion, his last name, wrote a tool for the postgress, for tracing the sprouts. There are two types of lobes in the Zgress, the so -called Lightweight Loki and Heavyweight Loki. Heavyweight is when you are the right table. Lightweight is that users are usually not visible, for example, Lock per page in Sharetbuffers. And [...] there, about how to debug Prod with these instruments. I do not know how public information this is, so I can’t talk about it, but we have such a thing as Continous Profiling, which constantly collects profiles from all Tasks in Prod'e. And it is very convenient. What it is built on, I don’t know, but obviously Overhead is low enough for it to work.
I understand. Some other tools are used. And what else do I have in short topics are reports of the Advanced Database Systems series 2020 reads the course of Andy Pavel this time. Sorry, I’ll kill me, I went a little from the microphone. I’m almost sure that I have never seen Google Stack, so I don’t know what they have Continous Profiling on, but [...] and Forget about her, I need to make my part for a request, throw it somewhere upstairs, somehow synchronize, because the knot is higher than me, it also works in a parallel in the form of a separate tank, and all this is much more complicated than shown in this The report, so this part is to me, she was not very impressed by me.
Well, yes, all this looks like a rather bleeding edge of the industry, where no one knows how to do it correctly, so they do everything as it seems right to them, and this is a single single approach. Part of the SQL server seemed interesting, it is reported that at some stage they made a separate operating system in Microsoft called SQL OS, this [...] bring. I will bring, I will not tell them. This is just the best thing to do, you don’t have to. Better do not bring, but tell ours. Well, I will be good. And on this note we say goodbye. Devzen.ru Telegram. Go to Spotify, add them the topics in Spotify, well, better in Telegram. So far, so far and until the next issue. Bye.
GraphSeg
For the implementation of GraphSeg, I chose a library called graphseg-python. Unfortunately, there’s no PyPI module available for it, and I spent several hours attempting to segment my test texts using the provided scripts. However, I was only able to get the script to run on my laptop within a separate virtual environment.
To proceed, I randomly selected the 412th episode to determine the optimal min_seg parameter for the GraphSeg algorithm. Briefly, the min_seg parameter is responsible for determining the minimum possible topic size. You can find more details about GraphSeg parameters in the original paper titled “Unsupervised Text Segmentation Using Semantic Relatedness Graphs” by Goran Glavas, Federico Nanni, and Simone Paolo Ponzetto.
I experimented with six different values for the parameter: 3, 6, 12, 24, 48, and 96. Additionally, I tested the algorithm on two languages: Russian (original) and English (translated using machine translation without any manual editing).
You can find the code and the resulting output below.
def graph_seg_windowdiff(df: pd.DataFrame, lang: str, verbose: bool = False, **kwargs) -> None:
episode = kwargs['episode']
topic_df = df[[f'{lang}_sentence', 'ground_truth']].groupby('ground_truth').agg(topic=(f'{lang}_sentence', lambda x: ''.join(x)))
topic_df['topic'] = topic_df['topic'].apply(lambda x: '|' + x[1:])
ground_truth = ''.join(topic_df['topic']).replace(' ', '')
# default k value for windowdiff
k = int(round(len(ground_truth) / (ground_truth.count('|') * 2.)))
metrics = []
all_topics = {}
for min_seg in tqdm([3, 6, 12, 24, 48, 96], disable=not verbose):
# files {episode}_episode_lang={lang}_min_seg={min_seg}_segments were built separately.
actual = open(f'../data/{episode}_ep_reference_lang={lang}_min_seg={min_seg}_segments.txt', 'r', encoding='utf8').read().strip()
topics = actual.split('\n\n')
actual = ''.join(['|' + t.replace(' ', '').replace('\n', '')[1:] for t in topics])
# for windowdiff ground truth and actual segmentation should have the same lengths
assert len(ground_truth) == len(actual), f'{ground_truth[:200]=}\n{actual[:200]}'
win_diff = windowdiff(ground_truth, actual, boundary="|", k=k)
metrics.append({
'algorithm': 'graph_seg',
'lang': lang,
'k': k,
'min_seg': min_seg,
'win_diff': win_diff,
'topics_count': len(topics)
})
all_topics[(min_seg,)] = topics
return pd.DataFrame(metrics), all_topics
ru_graph_seg_metrics_df, ru_segments_graph_seg = graph_seg_windowdiff(df, 'ru', episode=412)
ru_graph_seg_metrics_df
| algorithm | lang | k | min_seg | win_diff | topics_count | |
|---|---|---|---|---|---|---|
| 0 | graph_seg | ru | 4701 | 3 | 1.000000 | 143 |
| 1 | graph_seg | ru | 4701 | 6 | 1.000000 | 102 |
| 2 | graph_seg | ru | 4701 | 12 | 0.950011 | 62 |
| 3 | graph_seg | ru | 4701 | 24 | 0.651128 | 25 |
| 4 | graph_seg | ru | 4701 | 48 | 0.416700 | 10 |
| 5 | graph_seg | ru | 4701 | 96 | 0.459720 | 5 |
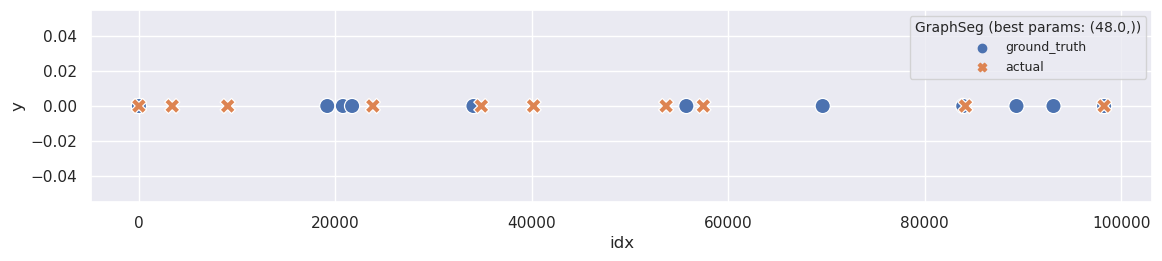
plot_segmentation_for_best_score(ru_graph_seg_metrics_df, ru_segments_graph_seg, ['min_seg'], ru_ground_truth, title='GraphSeg')
print_segmentation(ru_segments_graph_seg[(48,)], limit=130)
Всем привет! Вы слушаете подкаст DevZen выпуск номер 412, записанный 6 февраля 2023 года. Записываемся как всегда полным составом, кроме Светы, кроме Вани. Подкаст теперь есть на Spotify, если вы пропустили последний выпуск. А со мной этот подкаст ведет Валера. Здравствуй, Валера! Привет! Привет! Сколько у нас теперь слушателей на Spotify? Слушай, я еще не заходил. Вот хороший вопрос. Пока мы будем о чем-то говорить, [...] делайте больших компаний, не делайте больших банков. Ну, наверное, было бы здорово, но... Где мы такое видели? Нет, я просто пытаюсь понять это... Ну, как бы, у меня искаженное представление о реальности, что банки должны работать лучше, или они все-таки все так работают? Просто мне повезло с одним банком. Они все так работают, как только они становятся большими успехами. И не только про банки справедливо.
У вас в карьере не было такого, что вы объявляете баг bankruptcy и закрываете все старые баги? Нет, такого я не помню. Но обычно это происходит как триаж, что вот у нас баг, он там типа зарепорчен два года назад, и с тех пор мы много переписали, и никто снова на это не жаловался, давайте забьем. Потому что, скорее всего, это не актуально. Ну вот [...] кэш DNS, на случай, если он там забился, пока ты под VPN сидел. Но, притом, честно говоря, я ее сюда добавил, но как будто бы давно не пользовался. Я не помню, для чего мне это было нужно. Одна команда, которая выводит нормально информацию о двоем CPU и его частоте. У меня здесь помечено, что если в настройках вы искать, это там так просто не находится.
А еще, вот в ленексе, когда ты хочешь посмотреть, кто какие порты слушает, то ты набираешь на цитат, минус тул в палуны. И это легко запомнить, потому что тул в палуны звучит похоже на тюльпан. А в Mac такого нет, поэтому у меня здесь записано, как это сделать через LSF. Но это не все, чему я научился на этой неделе. В блоге компании Cybertech появился [...] других групп. И вы так можете сформираться в группы людей, которые смогут вместе что-то сделать, потому что вам, как минимум, нужен кто-то, кто умеет рисовать, кто-то, кто умеет программировать. Если у вас в игре есть какой-то текст, скорее всего кто-то, кто умеет писать хорошо. Бывают, конечно, уникумы, которые умеют делать это все, но даже этим уникумам 48 часов уложиться будет сложновато, чтобы успеть все сделать.
Еще, как правило, на многих джемах есть одна или две игры, которые построены вокруг процедурной музыки, что тоже отдельно круто. Я это не достаточно понимаю, чтобы по-настоящему оценить, что там происходит, но это очень впечатляет, как правило. Была тема в этот раз KORN. У нас команда получилась такая, что было два программиста, оба из которых к разработке игр имеют отношение только на джемах. Просто до [...] понятно. Просто у нас все было поломано, и мы все героически починили. Мы молодцы. И маркетинговые постмортумы. Вот этот постмортум не из таких, поэтому дикий респект им за это тоже. Вот, собственно, к постмортуму. Наверное, я попробую вкратце пересказать события и как у них система работает, но правда, наверное, если интересны детали, то стоит прямо открыть статью и посмотреть туда. Как у них устроен Backend?
У них есть центральная база данных, которая то ли MySQL, то ли CosmosDB, то ли CosmosDB, это такой MySQL, я не разобрался. Вот, но есть у них большая база данных, в которой хранится вся важная информация про состояние бизнеса. В эту базу данных ходят в основном через сервис, который они называют LegacyFassad. Кроме того, кажется, их ресторанные кассы тоже иногда ходят напрямую в базу данных. [...] лампстеку лет 10 назад, поэтому я прям вообще вот, ну в любом этом плане. Возможно, Саша добавит мне общего знания о базах данных тут. Вот. Но причину, которую, соответственно, вот ребята из DoDo в конце концов установили уже после инцидента, оказывается, причина была в кэше файловых дискриптерах MySQL. Что это вообще такое? Оказывается, в MySQL'е каждая таблица представлена в виде отдельного файла на операционной системе.
И чтобы доступаться к такой таблице, нужно открыть этот файл и получить файловый дискриптер. И для каждой вот сессии с базой данных тебе нужен свой собственный дискриптер для каждой таблицы, к которой ты доступаешься. Допустим, ты выполняешь SELECT с 5 джойнами, у тебя получается 6 таблиц и тебе нужно 6 файловых дискриптеров по одному дискриптеру на каждую из вот этих таблиц. Создавать эти дискриптеры, ну [...] внутренний кастомер какой-то, который тоже другой бизнес-юнит, и что другой бизнес-юнит имеет приоритет перед тем, чтобы отвечать веб-сайтам, это интересная идея, и вот то, что у них была возможность вот так контролировать ответ сервиса, вот это интересная тема. Ну, кстати, я так понимаю, что вот это у них возможность была, потому что у них разные вот эти источники заходят через разные микросервисы. А-а-а, я понял.
Ну, собственно, я вернусь тогда к своему набросу, который хотел Саша сделать, и скажи, Саша, а в Postgres там же нет такой системы, чтобы по файлу на таблицу? Там по много файлов на таблицу. Зависит от размера. То есть, у тебя в Postgres, когда его компилируешь, ты задаешь параметр конфигурации, ну или тот, кто тебя собирает в пакет, задает параметр конфигурации, называется размер сегмента. По [...] глубокая иерархия, и как человек, находящийся на директорской или C-позиции, вы вообще не будете иметь настоящую актуальную информацию, которая есть у людей, которые реально делают дела. Поэтому ваша попытка принять решение или сдать стратегию или что-то такое, она просто заведомо причина на провал, потому что вы слишком далеко от людей, исполняющих функцию, и вы физически, человеческо не можете это все объять, потому что это невозможно.
Что остается? Остается быть такой королевой. Ваша задача, у вас представительская функция, ваша задача формировать ценности компании. Как это делается? Вы их формулируете, про то, что такое ценность, мы поговорим чуть подальше, потому что не любые ценности полезны, некоторые хорошо звучат, но несут мало пользы. Кстати упражнения... Ну ладно, я потом к упражнениям перейду. И задача... Вот как бы... Энфорсмент этих ценностей состоит в чем? [...] вот, я понял. Угу, спасибо. Ну, и, соответственно, с iPhone это доступно, можно, если с кем-то садишь, садишь, можно на iPhone это поднять и показать. Что еще можно показать? Это эссоциативные сервера, в которые ты логинился. Ага. Эм, это интересная тема, которая, кажется, занес в темы слушателей несколько выпусков назад, но трюк не прокатил. Идея в следующем. Во-первых, ну, достаточно хорошо известен факт, что на
GitHub можно для любого юзернейма посмотреть зарегистрированные публичные ключи. GitHub.com slash username.keys и там весь список публичных ключей, которые ты добавил в свой GitHub. Это OK, потому что теоретически ключи публичные, поэтому с ним ничего опасного сделать нельзя. Ничего не раш... Нельзя авторизоваться, то и вене, все такое. Вот. Соответственно, через GitHub API, в принципе, не очень сложно написать бота, который просто обойдет всех пользователей [...] а потом подумали, о чем бы на Linux они не запустятся. И вроде как где-то в интернетах есть статья про то, как портировали SQL Server на Linux, я не читал, мне было не настолько интересно, но она как будто бы где-то есть. Ну вот такой пересказ. Мне, мне эта лекция повторюсь, не то чтобы сильно понравилась, хотя в пару моментов было прикольно, вопросов, возражений, комментариев.
Ну и ладно, пойдем тогда по темам наших слушателей. По темам наших слушателей. Пойдем, пойдем по темам очевоевых две. А так разве бывает в Telegram? В Telegram и Spotify разве можно две темы приносить? Слушайте... Просто все принесли темы в Spotify, а не в Telegram, а ты не смотришь в Spotify. Это бы многое объясняло. Хитрый слушатель без имени, которое можно увидеть, пишет «Уважаемые ведущие, [...] приноси. Нет, не буду. А ты приноси. Я буду приносить, не буду их рассказывать. Вот это просто самое лучшее, что можно сделать, не надо так. Лучше не приноси, но рассказывай наши. Ну ладно, я буду хорошим. И на этой ноте мы с вами прощаемся. DevZen.ru Telegram. Заходите в Spotify, добавляйте нам темы в Spotify, ну лучше в Telegram. Всем пока и до следующего выпуска. Пока.
en_graph_seg_metrics_df, en_graph_seg_segments = graph_seg_windowdiff(df, 'en', episode=412, verbose=True)
en_graph_seg_metrics_df
| algorithm | lang | k | min_seg | win_diff | topics_count | |
|---|---|---|---|---|---|---|
| 0 | graph_seg | en | 4655 | 3 | 1.000000 | 267 |
| 1 | graph_seg | en | 4655 | 6 | 0.997954 | 119 |
| 2 | graph_seg | en | 4655 | 12 | 0.838687 | 48 |
| 3 | graph_seg | en | 4655 | 24 | 0.625355 | 16 |
| 4 | graph_seg | en | 4655 | 48 | 0.504082 | 10 |
| 5 | graph_seg | en | 4655 | 96 | 0.578145 | 9 |
plot_segmentation_for_best_score(en_graph_seg_metrics_df, en_graph_seg_segments, ['min_seg'], en_ground_truth, title='GraphSeg Google Tranaslated')
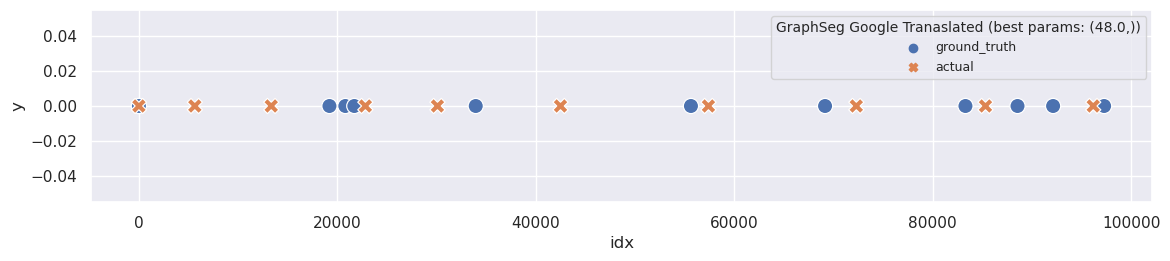
print_segmentation(en_graph_seg_segments[(48,)])
Hi all! You listen to the Devzen podcast issue number 412, recorded on February 6, 2023. We sign up as always with a full composition, except for Sveta, except Vani. There is now a podcast on Spotify if you missed the last issue. And with me this podokast is leading [...] a big problem once in a couple of months. But at some point it did not quite suit me, I decided to see how people solve this problem, found the third on Stack Overflow, Stack Overflow says that we do not solve this problem, and we must replace this problem.
I showed stubbornness, or stubbornness. Closed, possibly in combination with persistence. I showed stubbornness and went into a chatik with familiar subspressers and asked how they do it new, they probably already learned this as right. Here, they threw off a single builder for me, by the way, Stas threw [...] he is not quite a neuthy of the speaker, but he has been living in Canada for 20 years. Therefore, he knows English much better than me. And, it turns out, for the word ipigneite, I did not know this. There is no direct literal translation in the Russian language.
There is no synonym. There are remotely similar words, but there is a straight synonym in principle, in principle, does not exist. Surprisingly. And the meaning is that Sasha has more ass. And he, based on his experience, maybe ... It has an opinion that it will work, that it [...] when you start, you are given an abstract idea, and you need to make a game in 48 hours around this idea. Preferably working. This is not some kind of competition, you just made the game after 48 hours and were able to show. Congratulations, you are beautiful and magnificent.
In principle, nothing prevents you from participating in online, and some even do that. I really like the format of the Berlin site. I will organize guys who seem to be called Gamestorm Berlin. Here. And I don’t know whether this is everywhere, because I am always Jamil on the [...] already have this feeling that, damn it, we will not have time to collect it, make this work build, and every time in the last hours in front of the deadline, a working build is obtained. This is just the absolute magic of Jem. How does this process look like?
You, like, everyone saw your own independent component or ... Well, look, first you need to draw a line that you have ... The team usually has artists yet, and someone there, for example, writers. These people, in principle, work with other tools, but artists draw, and you usually communicate [...] the database. And since they did it already at ten o’clock in the evening, it was strong after the peak. And just the system automatically rose. At that moment, she coped. Here. This is a description of the incident. Before we turn to the conclusions to the issue of addition.
I may be distracted. I did not quite understand how the release rollback helped everything to rise. Can I again? The rollback of the release as such did not help much. He helped only because as his side effect was restarting all services. I understand. They all rebeted, they had [...] have do things. Therefore, your attempt to make a decision or pass a strategy or something like that, it is simply obviously the reason for failure, because you are too far from people who perform the function, and you are physically, humanly cannot bend it all, because it is impossible.
What remains? It remains to be such a queen. Your task, you have a representative function, is your task to form the values of the company. How it's done? You formulate them, about what value is, we will talk a little further away, because not any values are useful, some [...] but in Tab it will always be included, and with the speed of the local network it will be a system that is optimized to be a local disc, and not a game computer under Windows. Plus, many modern NASA, such as Cyanology, can in ... how it is ...
how can they be in the S3 or such cloud services. Cyanology has its own backup service. Interestingly, Dropbox has the smallest plans that you can subscribe is 2 terabytes. What is a little absurd, because if you imagine that you really occupied 2 terabytes, that is, the company that [...] the GitHub nicknames, then He will just say Okay, okay, I authorize you, dude, with this key. Here, and so, if you are SSH-are in this modified server, then the server can find out your nickname on Github. You used the same public key that you have registered with GitHub.
So far, while everyone is watching, right? Everything is clear? Here. Now a more disturbing variation on this topic begins. It consists in the fact that Okay, well, for example, we wrote such a cunning SSH server, but no one forces you to enter it, well, just don’t go to [...] made a separate operating system in Microsoft called SQL OS, this is a special operating system to twist the DBMS on it. There was once an idea, I forgot what it is called, about micro-man, or what it was called, Valer, when are you launching an Irlang on iron? United.
Unicernal, thanks. Here's how unicernal, only for the DBMS. And from the funny decisions that they made, that you are as a developer of the DBMS, you must spread YILD all over your code, because you are not on a real operating system, you are special, and there is no [...] to do, you don’t have to. Better do not bring, but tell ours. Well, I will be good. And on this note we say goodbye. Devzen.ru Telegram. Go to Spotify, add them the topics in Spotify, well, better in Telegram. So far, so far and until the next issue. Bye.
Unsupervised Topic Segmentation of Meetings with BERT Embeddings
The final method I’m exploring is unsupervised segmentation using BERT embeddings. This approach can encompass various techniques, such as default next sentence prediction-based methods or even K-nearest neighbor approaches built on BERT embeddings.
For this experiment, I’m using an implementation from pyconverse. The library’s maintainer utilizes NLTK’s TextTilingTokenizer to implement the algorithm described in the research paper. I’m applying this method to segment my own data to compare it with the vanilla TextTiling and GraphSeg approaches.
def sts_windowdiff(df: pd.DataFrame, lang: str, semantic_text_segmentation_impl, verbose: bool = False, **kwargs) -> None:
topic_df = df[[f'{lang}_sentence', 'ground_truth']].groupby('ground_truth').agg(topic=(f'{lang}_sentence', lambda x: ''.join(x)))
topic_df['topic'] = topic_df['topic'].apply(lambda x: '|' + x[1:])
ground_truth = ''.join(topic_df['topic']).replace(' ', '')
# default k value for windowdiff
k = int(round(len(ground_truth) / (ground_truth.count('|') * 2.)))
all_topics = {}
metrics = []
for threshold in tqdm([x/100 for x in range(0, 100, 5)], disable=not verbose):
topics = semantic_text_segmentation_impl.get_segments(threshold=threshold)
actual = ''.join(['|' + topic.replace('\n', '').replace(' ', '')[1:] for topic in topics])
actual = actual.replace(' ', '')
assert len(ground_truth) == len(actual), f'{len(ground_truth)=} {len(actual)=} {ground_truth[:100]=} {actual[:100]=}'
topics_count = len(topics)
# for windowdiff ground truth and actual segmentation should have the same lengths
assert len(ground_truth) == len(actual)
win_diff = windowdiff(ground_truth, actual, boundary="|", k=k)
metrics.append({
'algorithm': 'semantic_text_segmentation',
'lang': lang,
'threshold': threshold,
'win_diff': win_diff,
'topics_count': topics_count
})
all_topics[(threshold,)] = topics
return pd.DataFrame(metrics), all_topics
ru_sts_metrics_df, ru_sts_segments = sts_windowdiff(df, 'ru', SemanticTextSegmention(df, 'sentence'), verbose=True)
ru_sts_metrics_df
| algorithm | lang | threshold | win_diff | topics_count | |
|---|---|---|---|---|---|
| 0 | semantic_text_segmentation | ru | 0.00 | 0.397099 | 1 |
| 1 | semantic_text_segmentation | ru | 0.05 | 0.397099 | 1 |
| 2 | semantic_text_segmentation | ru | 0.10 | 0.397099 | 1 |
| 3 | semantic_text_segmentation | ru | 0.15 | 0.397099 | 1 |
| 4 | semantic_text_segmentation | ru | 0.20 | 0.397099 | 1 |
| 5 | semantic_text_segmentation | ru | 0.25 | 0.397099 | 1 |
| 6 | semantic_text_segmentation | ru | 0.30 | 0.397099 | 1 |
| 7 | semantic_text_segmentation | ru | 0.35 | 0.397099 | 1 |
| 8 | semantic_text_segmentation | ru | 0.40 | 0.397099 | 1 |
| 9 | semantic_text_segmentation | ru | 0.45 | 0.397099 | 1 |
| 10 | semantic_text_segmentation | ru | 0.50 | 0.397099 | 1 |
| 11 | semantic_text_segmentation | ru | 0.55 | 0.397099 | 1 |
| 12 | semantic_text_segmentation | ru | 0.60 | 0.397099 | 1 |
| 13 | semantic_text_segmentation | ru | 0.65 | 0.397099 | 1 |
| 14 | semantic_text_segmentation | ru | 0.70 | 0.397099 | 1 |
| 15 | semantic_text_segmentation | ru | 0.75 | 0.397099 | 1 |
| 16 | semantic_text_segmentation | ru | 0.80 | 0.397099 | 1 |
| 17 | semantic_text_segmentation | ru | 0.85 | 0.397099 | 1 |
| 18 | semantic_text_segmentation | ru | 0.90 | 0.401110 | 2 |
| 19 | semantic_text_segmentation | ru | 0.95 | 0.406864 | 4 |
The best results I obtained were for text that wasn’t even split into segments. Let’s examine the worst segmentation with a threshold set to 0.95:
plot_segmentation(ru_ground_truth, ru_sts_segments[(0.95,)], title='Semantic Text Segmentation (threshold=0.95)')
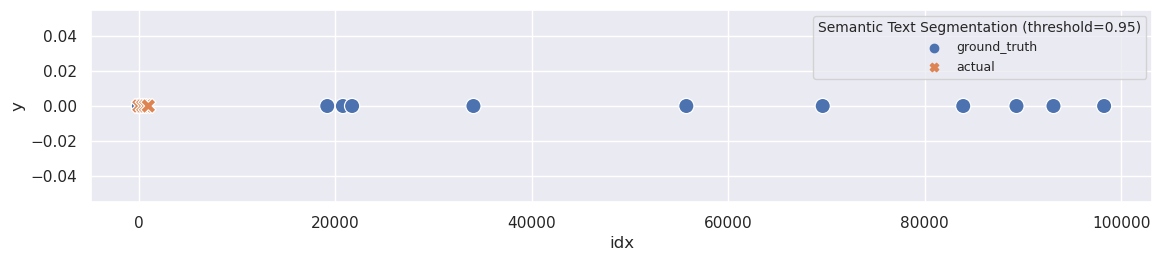
And what about best segmentation?
plot_segmentation_for_best_score(ru_sts_metrics_df, ru_sts_segments, ['threshold'], ru_ground_truth, title='Semantic Text Segmentation')
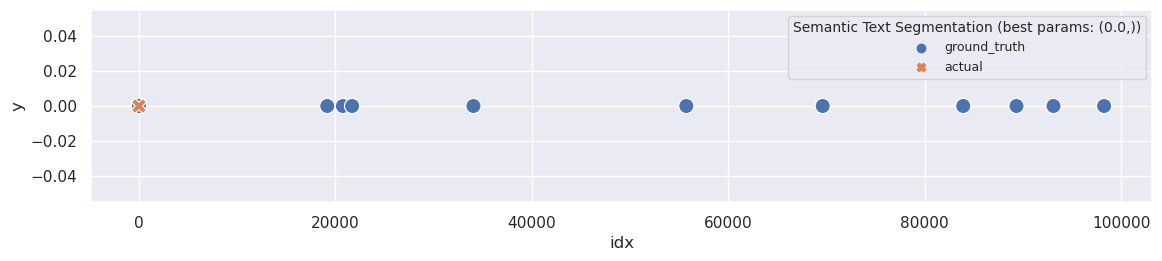
It appears to be quite poor but expected.
As I mentioned previously, pyconverse utilizes NLTK’s TextTilingTokenizer with similarity calculations based on BERT embeddings. Consequently, this implementation suffers from the same issue as the standard TextTilingTokenizer—it doesn’t support non-Latin languages. The TextTilingTokenizer.tokenize method simply removes all non-Latin characters (such as Cyrillic) from the text.
Let’s dive into the SemanticTextSegmention sources and see what can we do here:
import attr
import pandas as pd
import numpy as np
from .utils import load_sentence_transformer, load_spacy
from nltk.tokenize.texttiling import TextTilingTokenizer
from sklearn.metrics.pairwise import cosine_similarity
model = load_sentence_transformer()
nlp = load_spacy()
@attr.s
class SemanticTextSegmentation:
"""
Segment a call transcript based on topics discussed in the call using
TextTilling with Sentence Similarity via sentence transformer.
Paramters
---------
data: pd.Dataframe
Pass the trascript in the dataframe format
utterance: str
pass the column name which represent utterance in transcript dataframe
"""
data = attr.ib()
utterance = attr.ib(default='utterance')
def __attrs_post_init__(self):
columns = self.data.columns.tolist()
def get_segments(self, threshold=0.7):
"""
returns the transcript segments computed with texttiling and sentence-transformer.
Paramters
---------
threshold: float
sentence similarity threshold. (used to merge the sentences into coherant segments)
Return
------
new_segments: list
list of segments
"""
segments = self._text_tilling()
merge_index = self._merge_segments(segments, threshold)
new_segments = []
for i in merge_index:
seg = ' '.join([segments[_] for _ in i])
new_segments.append(seg)
return new_segments
def _merge_segments(self, segments, threshold):
segment_map = [0]
for index, (text1, text2) in enumerate(zip(segments[:-1], segments[1:])):
sim = self._get_similarity(text1, text2)
if sim >= threshold:
segment_map.append(0)
else:
segment_map.append(1)
return self._index_mapping(segment_map)
def _index_mapping(self, segment_map):
index_list = []
temp = []
for index, i in enumerate(segment_map):
if i == 1:
index_list.append(temp)
temp = [index]
else:
temp.append(index)
index_list.append(temp)
return index_list
def _get_similarity(self, text1, text2):
sentence_1 = [i.text.strip()
for i in nlp(text1).sents if len(i.text.split(' ')) > 1]
sentence_2 = [i.text.strip()
for i in nlp(text2).sents if len(i.text.split(' ')) > 2]
embeding_1 = model.encode(sentence_1)
embeding_2 = model.encode(sentence_2)
embeding_1 = np.mean(embeding_1, axis=0).reshape(1, -1)
embeding_2 = np.mean(embeding_2, axis=0).reshape(1, -1)
if np.any(np.isnan(embeding_1)) or np.any(np.isnan(embeding_2)):
return 1
sim = cosine_similarity(embeding_1, embeding_2)
return sim
def _text_tilling(self):
tt = TextTilingTokenizer(w=15, k=10)
text = '\n\n\t'.join(self.data[self.utterance].tolist())
segment = tt.tokenize(text)
segment = [i.replace("\n\n\t", ' ') for i in segment]
return segment
To extract this class from the library, only two modifications are required: overriding the load_sentence_transformer and load_spacy methods. Fortunately, these methods are quite straightforward:
import spacy
from sentence_transformers import SentenceTransformer
def load_sentence_transformer(model_name='all-MiniLM-L6-v2'):
model = SentenceTransformer(model_name)
return model
def load_spacy():
return spacy.load('en_core_web_sm')
The primary issue for non-English texts is that the maintainer utilizes an English-only model, all-MiniLM-L6-v2, for embeddings. My solution is to switch to a multilingual model, such as sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2.
I’ve copied and pasted this class below and made some improvements. First of all I’ve inlined load_sentence_transformer and load_spacy methods. Secondly I’ve extended __init__ method with add additional param — model name. And the last and I think one of the most valuable improvement is that I’ve replaced NLTK’s TextTilingTokenizer to the one I’ve changed earlier — TextTilingTokenizerExt:
import attr
import pandas as pd
import spacy
import numpy as np
from sklearn.metrics.pairwise import cosine_similarity
from sentence_transformers import SentenceTransformer
class SemanticTextSegmentationMultilingual:
"""
Segment a call transcript based on topics discussed in the call using
TextTilling with Sentence Similarity via sentence transformer.
Paramters
---------
data: pd.Dataframe
Pass the trascript in the dataframe format
utterance: str
pass the column name which represent utterance in transcript dataframe
"""
def __init__(self, data, utterance, model):
self.data = data
self.utterance = utterance
self.model = SentenceTransformer(model)
self.nlp = spacy.load('en_core_web_sm')
def __attrs_post_init__(self):
columns = self.data.columns.tolist()
def get_segments(self, threshold=0.7):
"""
returns the transcript segments computed with texttiling and sentence-transformer.
Paramters
---------
threshold: float
sentence similarity threshold. (used to merge the sentences into coherant segments)
Return
------
new_segments: list
list of segments
"""
segments = self._text_tilling()
merge_index = self._merge_segments(segments, threshold)
new_segments = []
for i in merge_index:
seg = ' '.join([segments[_] for _ in i])
new_segments.append(seg)
return new_segments
def _merge_segments(self, segments, threshold):
segment_map = [0]
for index, (text1, text2) in enumerate(zip(segments[:-1], segments[1:])):
sim = self._get_similarity(text1, text2)
if sim >= threshold:
segment_map.append(0)
else:
segment_map.append(1)
return self._index_mapping(segment_map)
def _index_mapping(self, segment_map):
index_list = []
temp = []
for index, i in enumerate(segment_map):
if i == 1:
index_list.append(temp)
temp = [index]
else:
temp.append(index)
index_list.append(temp)
return index_list
def _get_similarity(self, text1, text2):
sentence_1 = [i.text.strip() for i in self.nlp(text1).sents if len(i.text.split(' ')) > 1]
sentence_2 = [i.text.strip() for i in self.nlp(text2).sents if len(i.text.split(' ')) > 2]
embeding_1 = self.model.encode(sentence_1)
embeding_2 = self.model.encode(sentence_2)
embeding_1 = np.mean(embeding_1, axis=0).reshape(1, -1)
embeding_2 = np.mean(embeding_2, axis=0).reshape(1, -1)
if np.any(np.isnan(embeding_1)) or np.any(np.isnan(embeding_2)):
return 1
sim = cosine_similarity(embeding_1, embeding_2)
return sim
def _text_tilling(self):
tt = TextTilingTokenizerExt(w=200, k=40)
text = '\n\n\t'.join(self.data[self.utterance].tolist())
segment = tt.tokenize(text)
segment = [i.replace("\n\n\t", ' ') for i in segment]
return segment
As an initial attempt, I used the same model that the pyconverse author used, which is all-MiniLM-L6-v2:
ru_sts_ext_all_mini_lm_metrics_df, ru_sts_ext_all_mini_lm_segments = sts_windowdiff(df, 'ru', SemanticTextSegmentationMultilingual(df, 'sentence', 'all-MiniLM-L6-v2'), verbose=True)
ru_sts_ext_all_mini_lm_metrics_df
| algorithm | lang | threshold | win_diff | topics_count | |
|---|---|---|---|---|---|
| 0 | semantic_text_segmentation | ru | 0.00 | 0.397099 | 1 |
| 1 | semantic_text_segmentation | ru | 0.05 | 0.397099 | 1 |
| 2 | semantic_text_segmentation | ru | 0.10 | 0.397099 | 1 |
| 3 | semantic_text_segmentation | ru | 0.15 | 0.397099 | 1 |
| 4 | semantic_text_segmentation | ru | 0.20 | 0.397099 | 1 |
| 5 | semantic_text_segmentation | ru | 0.25 | 0.397099 | 1 |
| 6 | semantic_text_segmentation | ru | 0.30 | 0.397099 | 1 |
| 7 | semantic_text_segmentation | ru | 0.35 | 0.397099 | 1 |
| 8 | semantic_text_segmentation | ru | 0.40 | 0.397099 | 1 |
| 9 | semantic_text_segmentation | ru | 0.45 | 0.397099 | 1 |
| 10 | semantic_text_segmentation | ru | 0.50 | 0.397099 | 1 |
| 11 | semantic_text_segmentation | ru | 0.55 | 0.397099 | 1 |
| 12 | semantic_text_segmentation | ru | 0.60 | 0.397099 | 1 |
| 13 | semantic_text_segmentation | ru | 0.65 | 0.397099 | 1 |
| 14 | semantic_text_segmentation | ru | 0.70 | 0.397099 | 1 |
| 15 | semantic_text_segmentation | ru | 0.75 | 0.397099 | 1 |
| 16 | semantic_text_segmentation | ru | 0.80 | 0.397099 | 1 |
| 17 | semantic_text_segmentation | ru | 0.85 | 0.397099 | 1 |
| 18 | semantic_text_segmentation | ru | 0.90 | 0.397099 | 1 |
| 19 | semantic_text_segmentation | ru | 0.95 | 0.397099 | 1 |
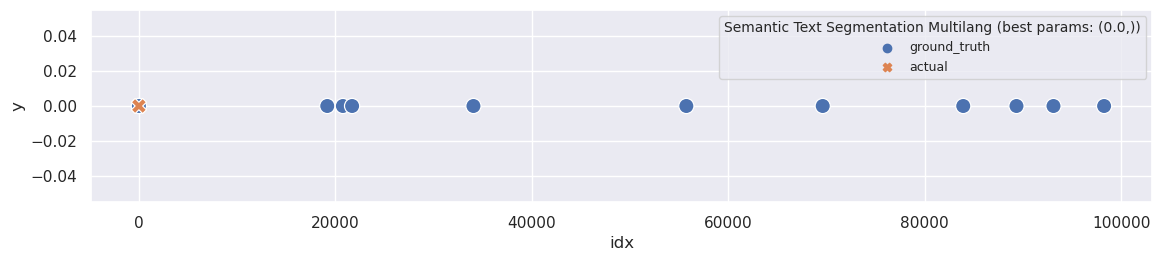
As expected, the results were quite poor. For all threshold values, the WindowDiff score was equal to 0.397099, and the segmenter did not split the text at all:
plot_segmentation_for_best_score(ru_sts_ext_all_mini_lm_metrics_df, ru_sts_ext_all_mini_lm_segments, ['threshold'], ru_ground_truth, title='Semantic Text Segmentation Multilang')
print_segmentation(ru_sts_ext_all_mini_lm_segments[(.0,)], limit=130)
Всем привет! Вы слушаете подкаст DevZen выпуск номер 412, записанный 6 февраля 2023 года. Записываемся как всегда полным составом, кроме Светы, кроме Вани. Подкаст теперь есть на Spotify, если вы пропустили последний выпуск. А со мной этот подкаст ведет Валера. Здравствуй, Валера! Привет! Привет! Сколько у нас теперь слушателей на Spotify? Слушай, я еще не заходил. Вот хороший вопрос. Пока мы будем о чем-то говорить, [...] приноси. Нет, не буду. А ты приноси. Я буду приносить, не буду их рассказывать. Вот это просто самое лучшее, что можно сделать, не надо так. Лучше не приноси, но рассказывай наши. Ну ладно, я буду хорошим. И на этой ноте мы с вами прощаемся. DevZen.ru Telegram. Заходите в Spotify, добавляйте нам темы в Spotify, ну лучше в Telegram. Всем пока и до следующего выпуска. Пока.
The next option is to replace all-MiniLM-L6-v2 with sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2. This model is more up-to-date and provides support for multiple languages:
ru_sts_ext_multilang_mini_lm_metrics_df, ru_sts_ext_multilang_mini_lm_segments = sts_windowdiff(df, 'ru', SemanticTextSegmentationMultilingual(df, 'sentence', 'sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2'), verbose=True)
ru_sts_ext_multilang_mini_lm_metrics_df
| algorithm | lang | threshold | win_diff | topics_count | |
|---|---|---|---|---|---|
| 0 | semantic_text_segmentation | ru | 0.00 | 0.397099 | 1 |
| 1 | semantic_text_segmentation | ru | 0.05 | 0.397099 | 1 |
| 2 | semantic_text_segmentation | ru | 0.10 | 0.397099 | 1 |
| 3 | semantic_text_segmentation | ru | 0.15 | 0.397099 | 1 |
| 4 | semantic_text_segmentation | ru | 0.20 | 0.397099 | 1 |
| 5 | semantic_text_segmentation | ru | 0.25 | 0.397099 | 1 |
| 6 | semantic_text_segmentation | ru | 0.30 | 0.397099 | 1 |
| 7 | semantic_text_segmentation | ru | 0.35 | 0.397099 | 1 |
| 8 | semantic_text_segmentation | ru | 0.40 | 0.397099 | 1 |
| 9 | semantic_text_segmentation | ru | 0.45 | 0.397099 | 1 |
| 10 | semantic_text_segmentation | ru | 0.50 | 0.397099 | 1 |
| 11 | semantic_text_segmentation | ru | 0.55 | 0.397099 | 1 |
| 12 | semantic_text_segmentation | ru | 0.60 | 0.397099 | 1 |
| 13 | semantic_text_segmentation | ru | 0.65 | 0.397099 | 1 |
| 14 | semantic_text_segmentation | ru | 0.70 | 0.397099 | 1 |
| 15 | semantic_text_segmentation | ru | 0.75 | 0.397099 | 1 |
| 16 | semantic_text_segmentation | ru | 0.80 | 0.358252 | 2 |
| 17 | semantic_text_segmentation | ru | 0.85 | 0.304282 | 4 |
| 18 | semantic_text_segmentation | ru | 0.90 | 0.313743 | 6 |
| 19 | semantic_text_segmentation | ru | 0.95 | 0.537717 | 18 |
Seems like an improvement: at least WindowDiff changes, and I obtain more than one segment for four different threshold values. The best WindowDiff score occurs at 0.85, resulting in four segments:
plot_segmentation_for_best_score(ru_sts_ext_multilang_mini_lm_metrics_df, ru_sts_ext_multilang_mini_lm_segments, ['threshold'], ru_ground_truth, title='Semantic Text Segmentation Multilang')
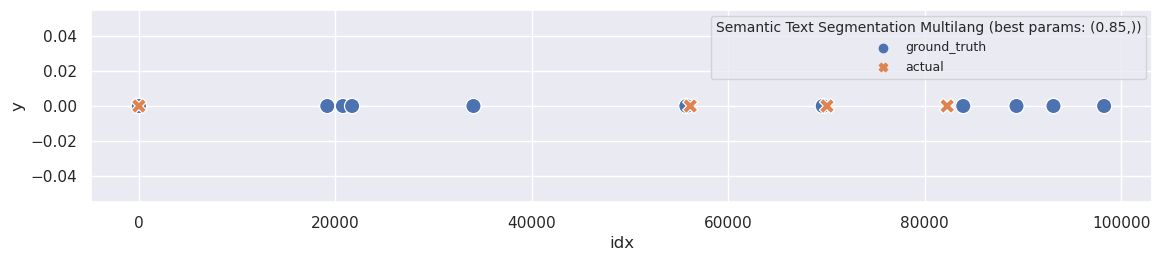
print_segmentation(ru_sts_ext_multilang_mini_lm_segments[(.85,)], limit=130)
Всем привет! Вы слушаете подкаст DevZen выпуск номер 412, записанный 6 февраля 2023 года. Записываемся как всегда полным составом, кроме Светы, кроме Вани. Подкаст теперь есть на Spotify, если вы пропустили последний выпуск. А со мной этот подкаст ведет Валера. Здравствуй, Валера! Привет! Привет! Сколько у нас теперь слушателей на Spotify? Слушай, я еще не заходил. Вот хороший вопрос. Пока мы будем о чем-то говорить, [...] В общем, я тут в рамках ангста на тему лей-оффов, и вообще о страшной экономической ситуации в индустрии. Начал... Не знаю, то, что начал, я, в принципе, давно не сочетался, не такое пролетало в Twitter-ленте, но тут я стал больше внимания обращать на посты по тематике. И вот мне в глаза попалась статья, потом не новая, аж 19 года, которая называется «А что директора-то делают?».
И речь в первую очередь про большие компании, потому что если компания маленькая, ну, человек на стол, на двести, когда директор еще действительно может даже знать всех этих людей лично, это в меньшей степени применимо. Просто уже нужно понимать, что тебя ждет, но ты как директор в такой маленькой компании еще можешь действительно на что-то влиять, принимать решения, и это даже будет не вредить. В [...] называется Dropbox. Но, на самом деле, не только Dropbox встречается такой проблемой. В общем, бывает так, что вы используете какой-то тул, построили вокруг него какие-то workflow. Какие-то workflow, возможно, не построили, но планировали и уже начали как бы платить за что-то, планируя немножко поменять вашу, ваш setup. Так, например, я в какой-то момент, ошибся, что у меня стало слишком много ролвок, и мне их жалко.
Я купил место в Dropbox, то есть, я сейчас плат по пользе для Dropbox, и у меня мои там сколько там, на этот момент 60 гб ролвок лежат как бы в Dropbox, и они как бы, я использую Dropbox в частности как offsite бэкап этих вещей, потому что я не хочу их то есть, у меня и так есть их копия дома, но да, поэтому [...] Writetube. Да, да, да. Capture Run — это прям отдельная своя собственная сущность. Это да, но это не позволяет мне иметь огромный мегакаталог. У меня все еще, поскольку есть экспортные фотографии, я примерно могу сориентироваться, когда я что-то снимал, и пойти и разархивировать нужную папку. Вот, но ты потом это делаешь экспорт уже обработанных фоток в какое-то одно место, или как? Да, в дурбокс тоже.
И ты потом в этом одном месте с помощью чего общие фотки глядишь? Просто у меня есть зависимости, короче. Во-первых, у меня есть фликра, во-вторых, у меня есть дурбокс, и можно просто сделать открытый вид фотки и полистать свои фотки по времени. Еще плюс у меня есть система именования, я более-менее, если я представляю, когда это примерно было, я могу просто по году сориентироваться. Ну, [...] приноси. Нет, не буду. А ты приноси. Я буду приносить, не буду их рассказывать. Вот это просто самое лучшее, что можно сделать, не надо так. Лучше не приноси, но рассказывай наши. Ну ладно, я буду хорошим. И на этой ноте мы с вами прощаемся. DevZen.ru Telegram. Заходите в Spotify, добавляйте нам темы в Spotify, ну лучше в Telegram. Всем пока и до следующего выпуска. Пока.
Let’s test this algorithm with English text. For the initial attempt, I’ll use the default SemanticTextSegmentation, and then I’ll try SemanticTextSegmentationMultilingual with two models: all-MiniLM-L6-v2 and sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2:
en_sts_metrics_df, en_sts_segments = sts_windowdiff(df, 'en', SemanticTextSegmention(df, 'en_translation'), verbose=True)
en_sts_metrics_df
| algorithm | lang | threshold | win_diff | topics_count | |
|---|---|---|---|---|---|
| 0 | semantic_text_segmentation | en | 0.00 | 0.395656 | 1 |
| 1 | semantic_text_segmentation | en | 0.05 | 0.358973 | 2 |
| 2 | semantic_text_segmentation | en | 0.10 | 0.352610 | 4 |
| 3 | semantic_text_segmentation | en | 0.15 | 0.400229 | 5 |
| 4 | semantic_text_segmentation | en | 0.20 | 0.547589 | 15 |
| 5 | semantic_text_segmentation | en | 0.25 | 0.558514 | 20 |
| 6 | semantic_text_segmentation | en | 0.30 | 0.810156 | 46 |
| 7 | semantic_text_segmentation | en | 0.35 | 0.947920 | 77 |
| 8 | semantic_text_segmentation | en | 0.40 | 0.967244 | 104 |
| 9 | semantic_text_segmentation | en | 0.45 | 1.000000 | 150 |
| 10 | semantic_text_segmentation | en | 0.50 | 1.000000 | 187 |
| 11 | semantic_text_segmentation | en | 0.55 | 1.000000 | 218 |
| 12 | semantic_text_segmentation | en | 0.60 | 1.000000 | 246 |
| 13 | semantic_text_segmentation | en | 0.65 | 1.000000 | 256 |
| 14 | semantic_text_segmentation | en | 0.70 | 1.000000 | 263 |
| 15 | semantic_text_segmentation | en | 0.75 | 1.000000 | 266 |
| 16 | semantic_text_segmentation | en | 0.80 | 1.000000 | 266 |
| 17 | semantic_text_segmentation | en | 0.85 | 1.000000 | 266 |
| 18 | semantic_text_segmentation | en | 0.90 | 1.000000 | 266 |
| 19 | semantic_text_segmentation | en | 0.95 | 1.000000 | 266 |
plot_segmentation_for_best_score(en_sts_metrics_df, en_sts_segments, ['threshold'], en_ground_truth, title='Semantic Text Segmentation: Google translated')
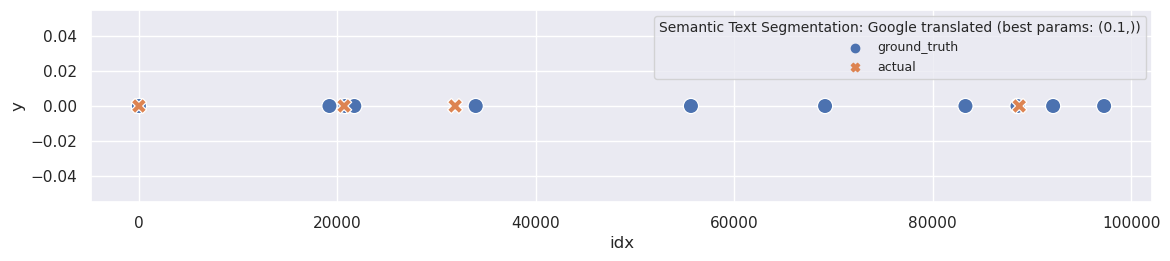
print_segmentation(en_sts_segments[(.1,)], limit=130)
Hi all! You listen to the Devzen podcast issue number 412, recorded on February 6, 2023. We sign up as always with a full composition, except for Sveta, except Vani. There is now a podcast on Spotify if you missed the last issue. And with me this podokast is leading Valera. Hello, Valera! Hello! Hello! How many listeners do we have on Spotify now? Listen, [...] update the link to the branch, and theoretically it will be more simple than if you had to do it with your hands. In practice, this is all the same, it seems to me, a very low-level tool, and Git, it is so cool, it can be a lot, but for some reason it is always so uncomfortable, and this is just a classic Git.
Somehow, in general, I corrected my earlier mistake, if someone is interested, please use, I have a good article that explains how to do it correctly. Thank you, I also have erata, we used to talk about one -payers on RISK5, is called Vision5.2, and Erata is that it seems to be a demand exceeded the offer, and the seller on AliExpress now sends customers [...] to mix on, say, enemies in the capsule and yell them there are definite, Unity has such a thing of tags, yell them with a certain tag. Further, a person who collects the level, he will simply continue to do it, and your game logic, then it will operate with this thing, it is just important for you to try not to change it later.
I don’t know, another jam, when I did Backend-Frontend, well, obviously, you will seem to agree on the interfaces, and usually you can agree on the interface quite quickly, or if you change something there, but this is usually not very big Deal between Bacquend -frontenD, and again, then you go, Debushes your Backend, and there, I don’t know, you are spinning in one local [...] like that. Thank you for going. Here, dear listeners, you see, we did not fully turn the topic, and we can come and expand it more fully. What else can be expanded, this topic is not in the bookmark for retelling. Firstly, I have a colleague Yang, Jan Nedvedsky, in my opinion, his last name, wrote a tool for the postgress, for tracing the sprouts.
There are two types of lobes in the Zgress, the so -called Lightweight Loki and Heavyweight Loki. Heavyweight is when you are the right table. Lightweight is that users are usually not visible, for example, Lock per page in Sharetbuffers. And this instrument allows you to touch, take the liberation of these sprouts, then collect statistics, on which Loki, how much we were waiting, they [...] bring. I will bring, I will not tell them. This is just the best thing to do, you don’t have to. Better do not bring, but tell ours. Well, I will be good. And on this note we say goodbye. Devzen.ru Telegram. Go to Spotify, add them the topics in Spotify, well, better in Telegram. So far, so far and until the next issue. Bye.
Now, let’s see what results I can achieve with the multilingual TextTiling algorithm and the English-only embedding model all-MiniLM-L6-v2, which I used in SemanticTextSegmentationMultilingual:
en_sts_ext_all_mini_lm_metrics_df, en_sts_ext_all_mini_lm_segments = sts_windowdiff(df, 'en', SemanticTextSegmentationMultilingual(df, 'en_translation', 'all-MiniLM-L6-v2'), verbose=True)
en_sts_ext_all_mini_lm_metrics_df
| algorithm | lang | threshold | win_diff | topics_count | |
|---|---|---|---|---|---|
| 0 | semantic_text_segmentation | en | 0.00 | 0.395656 | 1 |
| 1 | semantic_text_segmentation | en | 0.05 | 0.395656 | 1 |
| 2 | semantic_text_segmentation | en | 0.10 | 0.395656 | 1 |
| 3 | semantic_text_segmentation | en | 0.15 | 0.395656 | 1 |
| 4 | semantic_text_segmentation | en | 0.20 | 0.395656 | 1 |
| 5 | semantic_text_segmentation | en | 0.25 | 0.395656 | 1 |
| 6 | semantic_text_segmentation | en | 0.30 | 0.395656 | 1 |
| 7 | semantic_text_segmentation | en | 0.35 | 0.395656 | 1 |
| 8 | semantic_text_segmentation | en | 0.40 | 0.395656 | 1 |
| 9 | semantic_text_segmentation | en | 0.45 | 0.351863 | 2 |
| 10 | semantic_text_segmentation | en | 0.50 | 0.351863 | 2 |
| 11 | semantic_text_segmentation | en | 0.55 | 0.300591 | 4 |
| 12 | semantic_text_segmentation | en | 0.60 | 0.300591 | 4 |
| 13 | semantic_text_segmentation | en | 0.65 | 0.300990 | 7 |
| 14 | semantic_text_segmentation | en | 0.70 | 0.294116 | 10 |
| 15 | semantic_text_segmentation | en | 0.75 | 0.352395 | 13 |
| 16 | semantic_text_segmentation | en | 0.80 | 0.417742 | 16 |
| 17 | semantic_text_segmentation | en | 0.85 | 0.556530 | 19 |
| 18 | semantic_text_segmentation | en | 0.90 | 0.556530 | 19 |
| 19 | semantic_text_segmentation | en | 0.95 | 0.556530 | 19 |
plot_segmentation_for_best_score(en_sts_ext_all_mini_lm_metrics_df, en_sts_ext_all_mini_lm_segments, ['threshold'], en_ground_truth, title='Semantic Text Segmentation Multilang: Google translated')
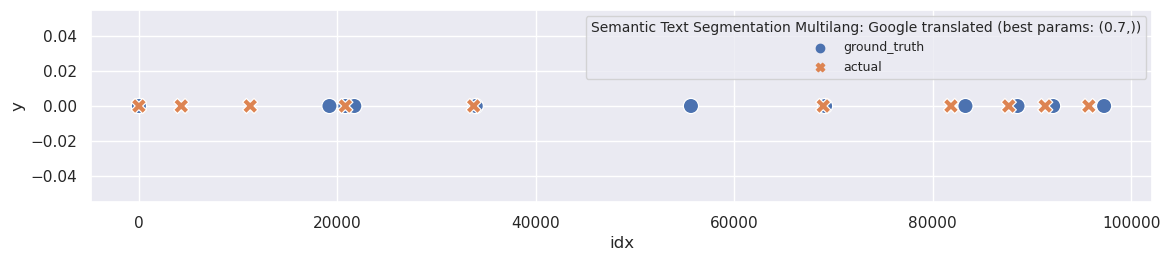
The last combination is the same as the previous one, but with the new multilingual model sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2:
en_sts_ext_multilang_mini_lm_metrics_df, en_sts_ext_multilang_mini_lm_segments = sts_windowdiff(df, 'en', SemanticTextSegmentationMultilingual(df, 'en_sentence', 'sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2'), verbose=True)
en_sts_ext_multilang_mini_lm_metrics_df
| algorithm | lang | threshold | win_diff | topics_count | |
|---|---|---|---|---|---|
| 0 | semantic_text_segmentation | en | 0.00 | 0.395656 | 1 |
| 1 | semantic_text_segmentation | en | 0.05 | 0.395656 | 1 |
| 2 | semantic_text_segmentation | en | 0.10 | 0.395656 | 1 |
| 3 | semantic_text_segmentation | en | 0.15 | 0.395656 | 1 |
| 4 | semantic_text_segmentation | en | 0.20 | 0.395656 | 1 |
| 5 | semantic_text_segmentation | en | 0.25 | 0.395656 | 1 |
| 6 | semantic_text_segmentation | en | 0.30 | 0.395656 | 1 |
| 7 | semantic_text_segmentation | en | 0.35 | 0.395656 | 1 |
| 8 | semantic_text_segmentation | en | 0.40 | 0.395656 | 1 |
| 9 | semantic_text_segmentation | en | 0.45 | 0.395656 | 1 |
| 10 | semantic_text_segmentation | en | 0.50 | 0.395656 | 1 |
| 11 | semantic_text_segmentation | en | 0.55 | 0.395656 | 1 |
| 12 | semantic_text_segmentation | en | 0.60 | 0.351863 | 2 |
| 13 | semantic_text_segmentation | en | 0.65 | 0.290955 | 4 |
| 14 | semantic_text_segmentation | en | 0.70 | 0.334656 | 5 |
| 15 | semantic_text_segmentation | en | 0.75 | 0.348610 | 8 |
| 16 | semantic_text_segmentation | en | 0.80 | 0.342636 | 10 |
| 17 | semantic_text_segmentation | en | 0.85 | 0.465362 | 17 |
| 18 | semantic_text_segmentation | en | 0.90 | 0.556530 | 19 |
| 19 | semantic_text_segmentation | en | 0.95 | 0.556530 | 19 |
plot_segmentation_for_best_score(en_sts_ext_multilang_mini_lm_metrics_df, en_sts_ext_multilang_mini_lm_segments, ['threshold'], en_ground_truth, title='Semantic Text Segmentation Multilang: Google translated')
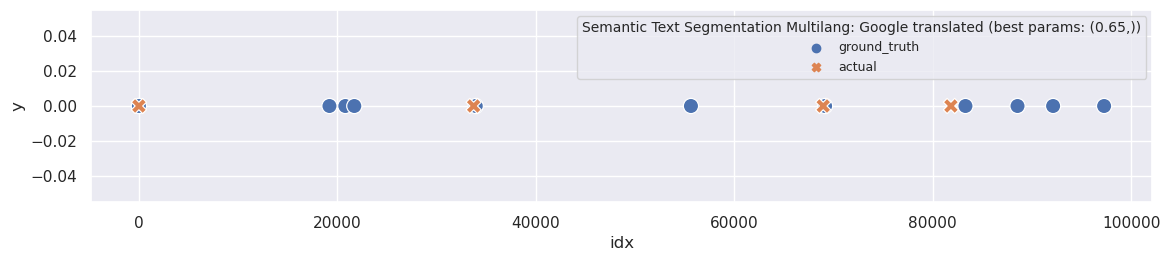
As I expect with a more modern model, the results were improved — the best score is 0.290955 for 0.65 threshold.
Concnulsion
In this article, I attempted to find the best existing text segmentation implementation. While I didn’t conduct an exhaustive study of all available algorithms, I did select some of the most popular ones: TextTiling, GraphSeg, and Semantic Segmentation.
Unfortunately, I must conclude that none of these implementations work well enough for my task. Below, I will present a table with all the WindowDiff metrics and showcase the segments that correspond to the best score:
ru_text_tiling_ext_metrics_df['algorithm'] = ru_text_tiling_ext_metrics_df['algorithm'] + '_ext'
ru_sts_ext_all_mini_lm_metrics_df['algorithm'] = ru_sts_ext_all_mini_lm_metrics_df['algorithm'] + '_ext_all_mini_lm'
ru_sts_ext_multilang_mini_lm_metrics_df['algorithm'] = ru_sts_ext_multilang_mini_lm_metrics_df['algorithm'] + '_ext_multilang_mini_lm'
ru_metrics = pd.concat([
ru_text_tiling_metrics_df,
ru_text_tiling_ext_metrics_df,
ru_graph_seg_metrics_df,
ru_sts_metrics_df,
ru_sts_ext_all_mini_lm_metrics_df,
ru_sts_ext_multilang_mini_lm_metrics_df,
])
min_windiff = ru_metrics['win_diff'].min()
ru_metrics[ru_metrics['win_diff'] == min_windiff][['algorithm', 'win_diff', 'topics_count']]
# ru_metrics[ru_metrics['topics_count'] > 1].sort_values('win_diff').head(40)
| algorithm | win_diff | topics_count | |
|---|---|---|---|
| 17 | semantic_text_segmentation_ext_multilang_mini_... | 0.304282 | 4 |
Semantic text segmentation with the modified Sentence Transformers model yielded the best overall result for Russian text. Let’s take another look at what this segmentation looks like:
plot_segmentation(ru_ground_truth, ru_sts_ext_multilang_mini_lm_segments[(.85,)], title='Semantic Text Segmentation: Winner')
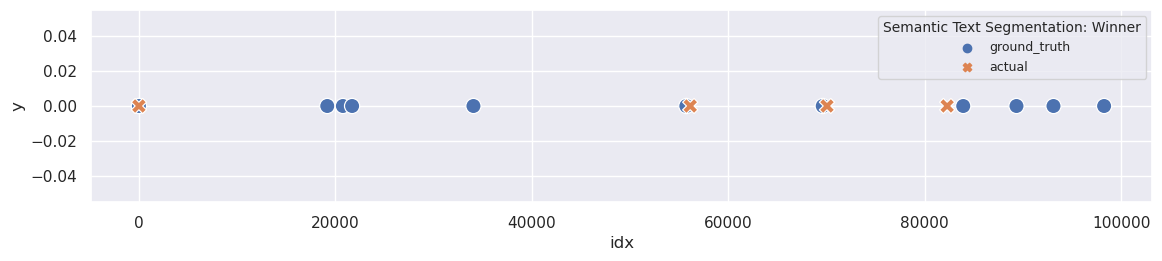
en_sts_ext_all_mini_lm_metrics_df['algorithm'] = en_sts_ext_all_mini_lm_metrics_df['algorithm'] + '_ext_all_mini_lm'
en_sts_ext_multilang_mini_lm_metrics_df['algorithm'] = en_sts_ext_multilang_mini_lm_metrics_df['algorithm'] + '_ext_multilang_mini_lm'
en_metrics = pd.concat([
en_text_tiling_metrics_df,
en_graph_seg_metrics_df,
en_sts_metrics_df,
en_sts_ext_all_mini_lm_metrics_df,
en_sts_ext_multilang_mini_lm_metrics_df,
])
min_windiff = en_metrics['win_diff'].min()
en_metrics[en_metrics['win_diff'] == min_windiff][['algorithm', 'win_diff', 'topics_count']]
| algorithm | win_diff | topics_count | |
|---|---|---|---|
| 13 | semantic_text_segmentation_ext_multilang_mini_lm | 0.290955 | 4 |
Only one algorithm achieved the best score: semantic text segmentation with the default model. Below is the segmentation plot for the winning algorithm:
plot_segmentation(en_ground_truth, en_sts_ext_multilang_mini_lm_segments[(.65,)], title='Semantic Text Segmentation: Google translated. Winner')
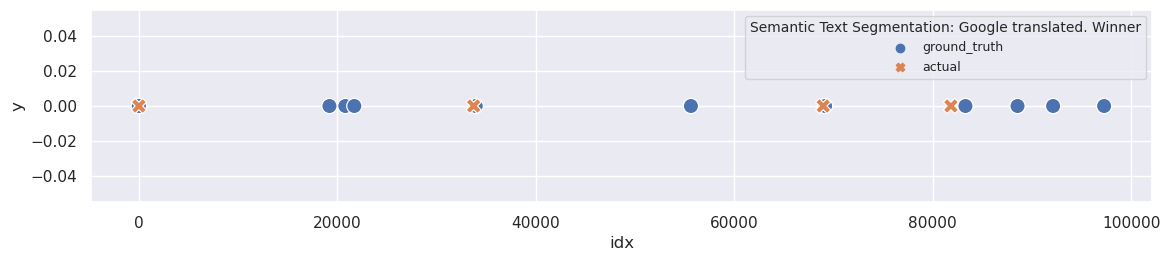
PS: You might be wondering why I segmented Google-translated texts. Here’s the reason: I wanted to test whether Google-translated text could be segmented more accurately than simply matching boundaries from the translation to the corresponding sentences in the original Russian text.
As you can see, even for Russian text with some modifications, I’ve achieved a basic level of segmentation. The next challenge is to find a way to improve upon this baseline segmentation.
PPS: Analyzing WindowDiff Metrics for 12 Episodes
To be honest, comparing different algorithms on a single episode is not ideal. So, in this section, I’m going to gather WindowDiff metrics for 12 episodes including 412th.
First, let’s compute WindowDiff for each episode and construct a dataframe containing all the metrics.
algorithms = {
'graph_seg': lambda df, lang, ep: graph_seg_windowdiff(df, lang, episode=ep),
'text_tiling_seg': lambda df, lang, _: text_tiling_windowdiff(df, lang, texttiling.TextTilingTokenizer if lang == 'en' else TextTilingTokenizerExt),
'semantic_text_seg': lambda df, lang, _: sts_windowdiff(df, lang, SemanticTextSegmentationMultilingual(df, f'{lang}_sentence', 'sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2'))
}
episodes = list(range(400, 413))
langs = ['ru', 'en']
results = {}
t = tqdm(total=(len(episodes) * len(langs) * len(algorithms)))
for ep in episodes:
df = pd.read_csv(f'../data/{ep}_ep_reference.csv')
for lang in langs:
for name, func in algorithms.items():
try:
metrics_df, segments = func(df, lang, ep)
results[f'{name}_{ep}_{lang}'] = {
'episode': ep,
'metrics': metrics_df,
'segments': segments
}
except Exception as e:
print(e)
print(name, ep, lang)
finally:
t.update(1)
for k, v in results.items():
v['metrics']['episode'] = v['episode']
ru_result_keys = {x for x in results.keys() if x.endswith('ru')}
ru_results = {k: v for k, v in results.items() if k in ru_result_keys}
ru_results_df = pd.concat([v['metrics'] for k, v in ru_results.items()])
ru_results_df
| algorithm | lang | k | min_seg | win_diff | topics_count | episode | sent_size | block_size | threshold | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | graph_seg | ru | 5566.0 | 3.0 | 1.000000 | 118 | 400 | NaN | NaN | NaN |
| 1 | graph_seg | ru | 5566.0 | 6.0 | 1.000000 | 84 | 400 | NaN | NaN | NaN |
| 2 | graph_seg | ru | 5566.0 | 12.0 | 1.000000 | 49 | 400 | NaN | NaN | NaN |
| 3 | graph_seg | ru | 5566.0 | 24.0 | 0.826407 | 22 | 400 | NaN | NaN | NaN |
| 4 | graph_seg | ru | 5566.0 | 48.0 | 0.373336 | 10 | 400 | NaN | NaN | NaN |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 20 | text_tiling | ru | 7663.0 | NaN | 0.884194 | 9 | 409 | 200.0 | 10.0 | NaN |
| 21 | text_tiling | ru | 7663.0 | NaN | 0.788119 | 9 | 409 | 200.0 | 20.0 | NaN |
| 22 | text_tiling | ru | 7663.0 | NaN | 0.650258 | 8 | 409 | 200.0 | 40.0 | NaN |
| 23 | text_tiling | ru | 7663.0 | NaN | 0.650258 | 8 | 409 | 200.0 | 80.0 | NaN |
| 24 | text_tiling | ru | 7663.0 | NaN | 0.650258 | 8 | 409 | 200.0 | 100.0 | NaN |
663 rows × 10 columns
ru_results_df = pd.concat([v['metrics'] for k, v in results.items()])
ru_results_df = ru_results_df.fillna('_')
ru_results_df['grouping_key'] = ru_results_df.apply(lambda x: f'{x["lang"]}__{x["algorithm"]}__{x["min_seg"]}__{x["sent_size"]}__{x["block_size"]}__{x["threshold"]}', axis='columns')
agg_df = ru_results_df.groupby(['grouping_key']).agg(
win_diff_median=('win_diff', np.median),
topic_count_median=('topics_count', np.median),
win_diff_mean=('win_diff', np.mean),
topic_count_mean=('topics_count', np.mean),
win_diff_std=('win_diff', np.std),
single_topic_count=('topics_count', lambda x: np.count_nonzero(x == 1))).reset_index().sort_values('win_diff_median')
agg_df
| grouping_key | win_diff_median | topic_count_median | win_diff_mean | topic_count_mean | win_diff_std | single_topic_count | |
|---|---|---|---|---|---|---|---|
| 56 | ru__graph_seg__96.0_________ | 0.357256 | 5.0 | 0.364165 | 5.384615 | 0.090165 | 0 |
| 21 | en__semantic_text_segmentation___________0.75 | 0.398142 | 5.0 | 0.417003 | 5.076923 | 0.095035 | 0 |
| 20 | en__semantic_text_segmentation___________0.7 | 0.400021 | 3.0 | 0.422666 | 2.692308 | 0.084790 | 3 |
| 19 | en__semantic_text_segmentation___________0.65 | 0.400021 | 1.0 | 0.401242 | 1.846154 | 0.063583 | 7 |
| 75 | ru__semantic_text_segmentation___________0.9 | 0.401380 | 6.0 | 0.419437 | 5.769231 | 0.111590 | 0 |
| ... | ... | ... | ... | ... | ... | ... | ... |
| 43 | en__text_tiling_____40.0__20.0___ | 1.000000 | 76.0 | 0.986665 | 77.692308 | 0.043428 | 0 |
| 44 | en__text_tiling_____40.0__40.0___ | 1.000000 | 75.0 | 0.983693 | 75.615385 | 0.050571 | 0 |
| 45 | en__text_tiling_____40.0__80.0___ | 1.000000 | 77.0 | 0.985418 | 77.692308 | 0.041864 | 0 |
| 34 | en__text_tiling_____20.0__40.0___ | 1.000000 | 150.0 | 0.990274 | 157.076923 | 0.035068 | 0 |
| 86 | ru__text_tiling_____20.0__80.0___ | 1.000000 | 135.0 | 0.989411 | 133.230769 | 0.038181 | 0 |
102 rows × 7 columns
I’d like to clarify the meaning of the single_topic_count column.
As observed earlier, some segmentation algorithms might treat the entire text as a single segment. I want to identify these algorithms that do not perform any segmentation. Therefore, the column single_topic_count indicates how many times the corresponding algorithm did not segment the text.
agg_df[agg_df['single_topic_count'] != 0].apply(lambda x: x['grouping_key'][:2], axis='columns').value_counts()
ru 18
en 15
Name: count, dtype: int64
So, 18 algorithms for Russian and 15 algorithms for English (each “algorithm” representing specific hyperparameters) did not perform well.
agg_df[(agg_df['single_topic_count'] != 0) & (agg_df['grouping_key'].str[:2] == 'ru')].sort_index()
| grouping_key | win_diff_median | topic_count_median | win_diff_mean | topic_count_mean | win_diff_std | single_topic_count | |
|---|---|---|---|---|---|---|---|
| 57 | ru__semantic_text_segmentation___________0.0 | 0.415831 | 1.0 | 0.411208 | 1.000000 | 0.027414 | 13 |
| 58 | ru__semantic_text_segmentation___________0.05 | 0.415831 | 1.0 | 0.411208 | 1.000000 | 0.027414 | 13 |
| 59 | ru__semantic_text_segmentation___________0.1 | 0.415831 | 1.0 | 0.411208 | 1.000000 | 0.027414 | 13 |
| 60 | ru__semantic_text_segmentation___________0.15 | 0.415831 | 1.0 | 0.411208 | 1.000000 | 0.027414 | 13 |
| 61 | ru__semantic_text_segmentation___________0.2 | 0.415831 | 1.0 | 0.411208 | 1.000000 | 0.027414 | 13 |
| 62 | ru__semantic_text_segmentation___________0.25 | 0.415831 | 1.0 | 0.411208 | 1.000000 | 0.027414 | 13 |
| 63 | ru__semantic_text_segmentation___________0.3 | 0.415831 | 1.0 | 0.411208 | 1.000000 | 0.027414 | 13 |
| 64 | ru__semantic_text_segmentation___________0.35 | 0.415831 | 1.0 | 0.411208 | 1.000000 | 0.027414 | 13 |
| 65 | ru__semantic_text_segmentation___________0.4 | 0.415831 | 1.0 | 0.411208 | 1.000000 | 0.027414 | 13 |
| 66 | ru__semantic_text_segmentation___________0.45 | 0.415831 | 1.0 | 0.411208 | 1.000000 | 0.027414 | 13 |
| 67 | ru__semantic_text_segmentation___________0.5 | 0.415831 | 1.0 | 0.411208 | 1.000000 | 0.027414 | 13 |
| 68 | ru__semantic_text_segmentation___________0.55 | 0.415831 | 1.0 | 0.411208 | 1.000000 | 0.027414 | 13 |
| 69 | ru__semantic_text_segmentation___________0.6 | 0.415831 | 1.0 | 0.411208 | 1.000000 | 0.027414 | 13 |
| 70 | ru__semantic_text_segmentation___________0.65 | 0.415831 | 1.0 | 0.411208 | 1.000000 | 0.027414 | 13 |
| 71 | ru__semantic_text_segmentation___________0.7 | 0.415831 | 1.0 | 0.411208 | 1.000000 | 0.027414 | 13 |
| 72 | ru__semantic_text_segmentation___________0.75 | 0.415831 | 1.0 | 0.411208 | 1.000000 | 0.027414 | 13 |
| 73 | ru__semantic_text_segmentation___________0.8 | 0.415831 | 1.0 | 0.402302 | 1.153846 | 0.040576 | 11 |
| 74 | ru__semantic_text_segmentation___________0.85 | 0.415607 | 3.0 | 0.420757 | 2.461538 | 0.088210 | 3 |
Out of the 20 semantic text segmentation variations, 18 failed to split a Russian text into segments.
agg_df[(agg_df['single_topic_count'] != 0) & (agg_df['grouping_key'].str[:2] == 'en')].sort_index()
| grouping_key | win_diff_median | topic_count_median | win_diff_mean | topic_count_mean | win_diff_std | single_topic_count | |
|---|---|---|---|---|---|---|---|
| 6 | en__semantic_text_segmentation___________0.0 | 0.415830 | 1.0 | 0.411684 | 1.000000 | 0.027740 | 13 |
| 7 | en__semantic_text_segmentation___________0.05 | 0.415830 | 1.0 | 0.411684 | 1.000000 | 0.027740 | 13 |
| 8 | en__semantic_text_segmentation___________0.1 | 0.415830 | 1.0 | 0.411684 | 1.000000 | 0.027740 | 13 |
| 9 | en__semantic_text_segmentation___________0.15 | 0.415830 | 1.0 | 0.411684 | 1.000000 | 0.027740 | 13 |
| 10 | en__semantic_text_segmentation___________0.2 | 0.415830 | 1.0 | 0.411684 | 1.000000 | 0.027740 | 13 |
| 11 | en__semantic_text_segmentation___________0.25 | 0.415830 | 1.0 | 0.411684 | 1.000000 | 0.027740 | 13 |
| 12 | en__semantic_text_segmentation___________0.3 | 0.415830 | 1.0 | 0.411684 | 1.000000 | 0.027740 | 13 |
| 13 | en__semantic_text_segmentation___________0.35 | 0.415830 | 1.0 | 0.411684 | 1.000000 | 0.027740 | 13 |
| 14 | en__semantic_text_segmentation___________0.4 | 0.415830 | 1.0 | 0.411684 | 1.000000 | 0.027740 | 13 |
| 15 | en__semantic_text_segmentation___________0.45 | 0.415830 | 1.0 | 0.411684 | 1.000000 | 0.027740 | 13 |
| 16 | en__semantic_text_segmentation___________0.5 | 0.415830 | 1.0 | 0.411684 | 1.000000 | 0.027740 | 13 |
| 17 | en__semantic_text_segmentation___________0.55 | 0.415830 | 1.0 | 0.412280 | 1.076923 | 0.027719 | 12 |
| 18 | en__semantic_text_segmentation___________0.6 | 0.415830 | 1.0 | 0.408081 | 1.230769 | 0.032176 | 11 |
| 19 | en__semantic_text_segmentation___________0.65 | 0.400021 | 1.0 | 0.401242 | 1.846154 | 0.063583 | 7 |
| 20 | en__semantic_text_segmentation___________0.7 | 0.400021 | 3.0 | 0.422666 | 2.692308 | 0.084790 | 3 |
Similarly, in the case of English, 15 out of 20 semantic segmentations were unable to split the text into segments.
What’s particularly intriguing is that only the semantic segmentation algorithms proved unsuccessful in segmenting both English and Russian texts.
And the winners are…
agg_df[(agg_df['single_topic_count'] == 0) & (agg_df['grouping_key'].str[:2] == 'ru')].sort_values('win_diff_median').head(5)
| grouping_key | win_diff_median | topic_count_median | win_diff_mean | topic_count_mean | win_diff_std | single_topic_count | |
|---|---|---|---|---|---|---|---|
| 56 | ru__graph_seg__96.0_________ | 0.357256 | 5.0 | 0.364165 | 5.384615 | 0.090165 | 0 |
| 75 | ru__semantic_text_segmentation___________0.9 | 0.401380 | 6.0 | 0.419437 | 5.769231 | 0.111590 | 0 |
| 54 | ru__graph_seg__48.0_________ | 0.436339 | 10.0 | 0.434767 | 9.692308 | 0.102372 | 0 |
| 90 | ru__text_tiling_____200.0__40.0___ | 0.503565 | 14.0 | 0.540059 | 13.615385 | 0.111870 | 0 |
| 88 | ru__text_tiling_____200.0__100.0___ | 0.503609 | 13.0 | 0.546321 | 13.461538 | 0.104181 | 0 |
agg_df[(agg_df['single_topic_count'] == 0) & (agg_df['grouping_key'].str[:2] == 'en')].sort_values('win_diff_median').head(5)
| grouping_key | win_diff_median | topic_count_median | win_diff_mean | topic_count_mean | win_diff_std | single_topic_count | |
|---|---|---|---|---|---|---|---|
| 21 | en__semantic_text_segmentation___________0.75 | 0.398142 | 5.0 | 0.417003 | 5.076923 | 0.095035 | 0 |
| 22 | en__semantic_text_segmentation___________0.8 | 0.435128 | 9.0 | 0.464065 | 8.230769 | 0.094496 | 0 |
| 5 | en__graph_seg__96.0_________ | 0.445946 | 8.0 | 0.459595 | 8.153846 | 0.068864 | 0 |
| 3 | en__graph_seg__48.0_________ | 0.504082 | 9.0 | 0.483979 | 9.076923 | 0.073587 | 0 |
| 23 | en__semantic_text_segmentation___________0.85 | 0.519998 | 13.0 | 0.551627 | 13.076923 | 0.109397 | 0 |
GraphSeg with min_seg values of 96 and 48, along with Semantic Text Segmentation using a 0.9 threshold, exhibited the best performance. While TextTiling showed some effectiveness, it didn’t meet my desired expectations.
On the other hand, for English texts, the WindowDiff metric is slightly lower, but GraphSeg with the same min_seg values stands out among the winners. Surprisingly, none of the “versions” of the TextTiling algorithm are present in the list of top performers.